
基础计算机网络
2022-03-20 / ryanxw
计算机网络和互联网
- 什么是Internet ?
- 节点:主机,路由器,交换机
- 边:通信链路
- 什么是协议?
- 通信过程中需要遵守的规则集合,如TCP,IP,FTP,HTTP等。
- 格式
- 次序
- 通信过程中需要遵守的规则集合,如TCP,IP,FTP,HTTP等。
- 网络边缘
- 主机
- 应用程序
- 应用通信模式:
- CS模式
- 对等模式(peer to peer)
- 传输方式:
- TCP
- 三次握手建立连接
- 可靠数据传输:确认机制,重传机制
- 流量控制:防止发送方淹没接收方
- 拥塞控制:网络速率降低时,发送方降低发送速率
- 应用:HTTP,FTP
- UDP
- 无连接
- 不可靠
- 无流量控制
- 无拥塞控制
- 应用:流媒体,远程会议,DNS
- TCP
- 应用通信模式:
- 接入网、物理媒体
- 接入网
- 有线 or 无线通信链路
- 网络带宽bps(bits per second)
- 接入网的方式
- 原来方式:调制解调器modem(猫),借用电话线,完成将电路信号转为网络信号。
- 缺点:带宽很小,上网电话不能同时使用
- 改进:原有的模式
- 0~4kHz用于电话
- 4kHz以上仍然使用调制和反调制的模式,非对称分割(一段用于上传,一段用于下载)
- 现有方式:铺专线,光纤入户
- 原来方式:调制解调器modem(猫),借用电话线,完成将电路信号转为网络信号。
- 物理媒体
- 导引型媒体(看得到摸得着)
- 同轴电缆
- 光纤(安全)
- 双绞线
- 非导引型媒体(开放的空间无形的)
- 电磁波
- 光信号
- 卫星
- wide-area
- 3G,4G,5G
- 导引型媒体(看得到摸得着)
- 接入网
- 网络核心:互相连着的路由器,起着数据交换的作用
- 分组交换(互联网大多使用此)
- 存储转发
- 不存储转发就变成网络独享了,不能共享
- 虚电路网络(TCP)
- 数据表网络(UDP)
- 存储转发
- 线路交换(电路交换,用于电话网)
- 时分
- 频分
- 波分
- 码分(CDM)
- 采用接入的方式称为CDMA
- 分组交换(互联网大多使用此)
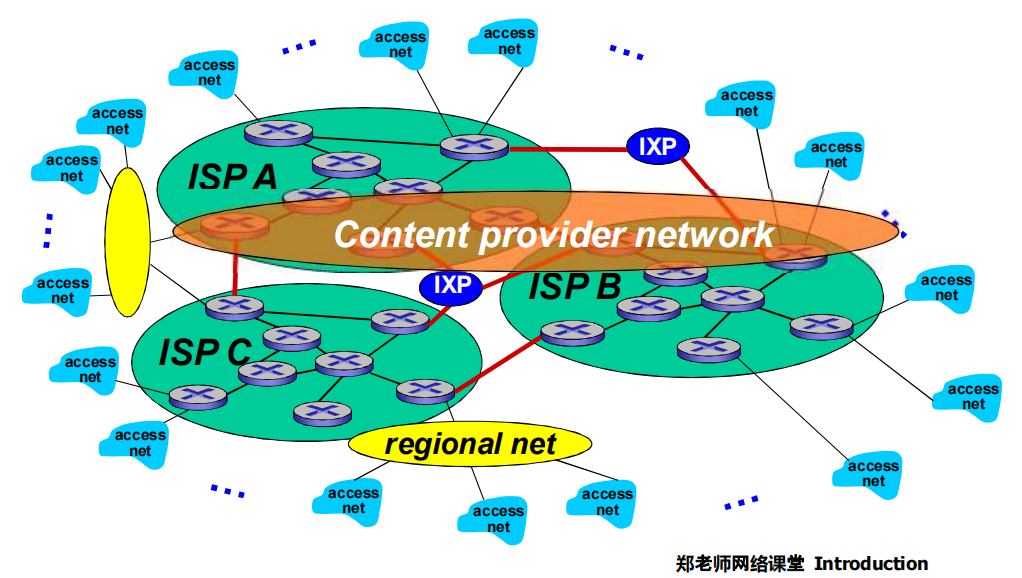
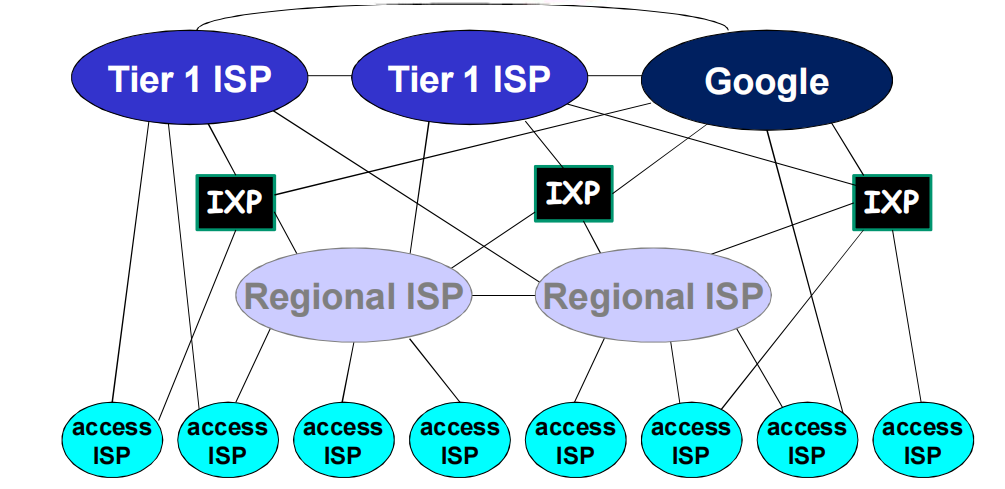
- Internet/ISP 结构
- 端接入ISPs(Internet Service Providers)连接到互联网
- ISPs之间必须互联
- 每两个连接不可取, 复杂度:$O(n^2)$
- 分治,区域性互相连接即可
- 性能:丢包、延时、吞吐量
- 分组丢失和延时的发生原因:
- 分组到达链路的速率超过了链路输出能力
- 分组排队,传输时延
- 丢包
- 取决于路由器的缓冲队列的大小。不可能无限大,尽管不丢包,但是体验感差
- 延时
- 节点处理时延:检测bit差错,分析首部决定发向哪里
- 排队时延:路由器的拥塞程度
- 传输时延:链路 带宽R,分组长度L,时延值= $L / R$,称为存储转发时延
- 传播时延:耗费在链路上的传播时延,链路长度d,传播速度s,时延值=$d/s$
- 吞吐量
- 源端和目标端之间的传输数据量(数据量/单位时间)
- 瞬间吞吐量:某个时间点
- 平均吞吐量:某个时间段
- 源端和目标端之间的传输数据量(数据量/单位时间)
- 分组丢失和延时的发生原因:
- 协议层次、服务模型
- 服务类型
- 面向连接TCP
- 无连接 UDP
- 协议层次
- PDU:协议数据单元
- 头部 + (n+1)层的SDU(Service Data Unit)
- 当SDU太大时需要分片,加上头部变成多个PDU;SDU太小时,多个组合起来加一个头部变成PDU;
- 网络层次
- 应用层:报文message
- 传输层:报文段:TCP段,UDP数据报
- 网络层:分组Packet,无连接时为数据包datagram,在链路层点到点之间的服务之上提供了端到端的服务
- 链路层:帧frame
- 物理层:位bit
- PDU:协议数据单元
- 服务类型
应用层
- 应用层协议原理
- Web和HTTP
- FTP
- Email(SMTP,POP3,IMAP)
- DNS
- P2P应用
- CDN(内容分发网络 Content Delivery Network)
- 视频流量占用大部分的带宽,如何并发的为那么多用户提供服务?挑战点:
- 规模性:单服务器无法服务大量用户
- 异构性:不同用户有不同的能力,比如有线接入和无线接入,其带宽容量不同
- 存储视频的流化方式(DASH动态自适应协议:Dynamic Adaptive Streaming over HTTP):上线视频时,预先部署,设置成不同清晰度的版本,分成每一块,设置URL放置到告示文件(manifest file)中供client去获取,也可以保证在观看中动态的切换清晰度,流化服务。
- client首先要获取manifest file,然后解析
- 解析完成后根据自己的需求,网络的带宽,缓存能力等实时情况动态调整去各个服务器获取每个块的流化信息
- 各个块的流化信息是预先部署到服务器上的。
- 单个服务器的问题有哪些?
- client访问到svr的路由器跳数太多
- 重复的流量太多,浪费网络资源
- 单点故障
- 周边网络拥塞
- 解决方案:CDN
- 分布式的部署到各个地点Cache Server
- 预先将内容存储到这些Cache Server
- 用户访问Svr时,根据域名解析重定向到距离用户最近的Cache Server
- CDN部署策略:
- local ISP
- 优点:距离用户最近,服务质量高
- 缺点:节点太多,维护费用高
- bring home
- 优点:节点少,只选择关键的位置,也距离用户不算远,服务质量不错
- 缺点:client访问经过路由器跳数略多
- local ISP
- 视频流量占用大部分的带宽,如何并发的为那么多用户提供服务?挑战点:
TCP套接字编程
- 数据结构 hostent
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct hostent
{
char *h_name; // 主机域名
char **h_aliases; // 主机域名别名
int h_addrtype; // 主机ip地址类型,ipv4(AF_INET) ipv6(AF_INET6)
int h_length; // ip地址的长度
char **h_addr_list; // 主机的ip地址 (以网络字节序存储)
};
/** 该函数通过域名获取IP地址,Client端调用该函数获取Server端的IP
* 传入参数:域名 or 主机名
* 返回值:
成功返回:struct hostent结构体
失败返回: NULL
*/
struct hostent *gethostbyname(const char *name); - 数据结构 sockaddr_in
1
2
3
4
5
6
7
8
9
10
11struct **sockaddr_in
{
short sin_family; // 地址族
unsigned short sin_port; // port
struct in_addr sin_addr; // IP地址
char sin_zero[8]; // 对齐
};**
struct in_addr {
unsigned long s_addr; // load with inet_aton()
}; - 数据结构 sockaddr
1
2
3
4struct sockaddr{
sa_family_t sin_family; //地址族(Address Family),也就是地址类型
char sa_data[14]; //IP地址和端口号
}; - sockaddr 和 sockaddr_in 的区别
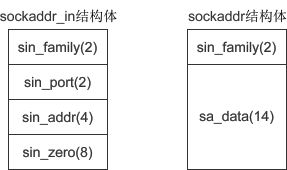 sockaddr 和 sockaddr_in 的长度相同,都是16字节,只是将IP地址和端口号合并到一起,用一个成员 sa_data 表示。要想给 sa_data 赋值,必须同时指明IP地址和端口号,例如”127.0.0.1:80“,遗憾的是,没有相关函数将这个字符串转换成需要的形式,也就很难给 sockaddr 类型的变量赋值,所以使用 sockaddr_in 来代替。这两个结构体的长度相同,强制转换类型时不会丢失字节,也没有多余的字节。
sockaddr 和 sockaddr_in 的长度相同,都是16字节,只是将IP地址和端口号合并到一起,用一个成员 sa_data 表示。要想给 sa_data 赋值,必须同时指明IP地址和端口号,例如”127.0.0.1:80“,遗憾的是,没有相关函数将这个字符串转换成需要的形式,也就很难给 sockaddr 类型的变量赋值,所以使用 sockaddr_in 来代替。这两个结构体的长度相同,强制转换类型时不会丢失字节,也没有多余的字节。 - Server端 https://man7.org/linux/man-pages/dir_section_3.html (man手册)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44/*
1. domain:AF_INET、AF_INET6、AF_LOCAL
2. type:SOCK_STEAM、SOCK_DGRAM
3. protocol: 默认0,会根据type自动选择
*/
int welcome_fd = socket(AF_INET, SOCK_STREAM, 0); // 用于监听client的请求
struct sockaddr_in sin;
sin.sin_family = AF_INET;
sin.sin_port = htons(24);
sin.sin_addr.s_addr = htonl(INADDR_ANY) // INADDR_ANY表示本机的任意一个IP
int ret = bind(welcome_fd, (struct sockaddr*)&sin, sizeof(sin))
if (ret != 0) { // 0 成功 -1 失败
return;
}
/*
1. svr端的socket fd
2. 限制套接字监听队列中未完成的连接数
*/
int ret = listen(welcome_fd, 5);
if (ret != 0) { // 0 成功 -1 失败
return;
}
struct sockaddr_in client_addr;
memset((char*)&client_addr, 0, sizeof(client_addr));
int client_addr_len = sizeof(client_addr);
char recv_buff[128];
while(1) {
// 1. 接收一个新的client连接
int connect_client_fd = accept(welcome_fd, (struct sockaddr*)&client_addr, &client_addr_len);
recv(connect_client_fd, recv_buff, sizeof(recv_buff), 0);
// 2. 处理请求
// 封装信息,假设char* send_buf[]
// 3. 发送给client
// https://man7.org/linux/man-pages/man3/send.3p.html
send(connect_client_fd, send_buf, sizeof(send_buf), 0);
close(connect_client_fd);
}](/2022/03/20/%E5%9F%BA%E7%A1%80%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/3.png) 本地字节序转化为网络字节序的函数,位于头文件<arpa/inet.h>中 https://linux.die.net/man/3/htonl
本地字节序转化为网络字节序的函数,位于头文件<arpa/inet.h>中 https://linux.die.net/man/3/htonl - Client端
1
2
3
4
5
6
7
8
9
10
11
12
13client_fd = socket(AF_INET, SOCK_STEAM, 0);
struct sockaddr_in sin;
sin.sin_family = AF_INET;
sin.sin_port = htons(24);
sin.sin_addr.s_addr = htonl(INADDR_ANY) // INADDR_ANY表示本机的任意一个IP
connect(client_fd, (struct sockaddr*)&sin, sizeof(sin));
char send_buf[128];
char recv_buf[128];
send(client_fd, send_buf, sizeof(send_buf), 0);
recv(client_fd, recv_buff, sizeof(recv_buff), 0); - 流程图
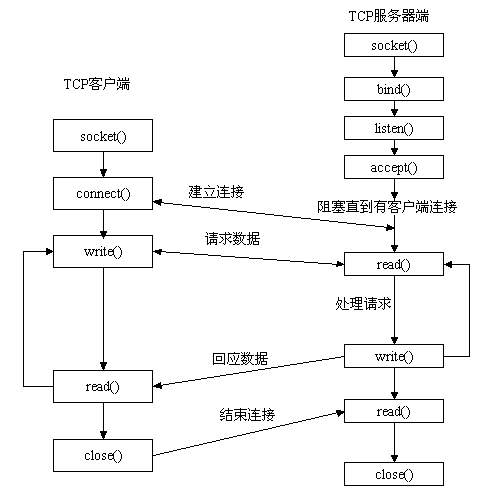
- TCP字节流的服务,不提供边界划分的功能,则需要应用层自己去设定协议解包
UDP套接字编程
- 无连接,不用握手,发送端在每一个报文中明确指定目标的IP和Port
- 服务器必须从收到的分组中提取出发送端的IP地址和Port
- 传输的数据可能乱序,可能丢失
- Server端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int svr_fd = socket(AF_INET, SOCK_DGRAM, 0);
struct sockaddr_in sin;
sin.sin_family = AF_INET;
sin.sin_port = htons(24);
sin.sin_addr.s_addr = htonl(INADDR_ANY) // INADDR_ANY表示本机的任意一个IP
bind(svr_fd, (struct sockaddr*)&sin, sizeof(sin));
struct sockaddr_in client_addr;
char recv_buf[128];
char send_buf[128];
recvfrom(svr_fd, recv_buf, sizeof(recv_buf), 0, (struct sockaddr*)&client_addr, &sizeof(client_addr));
sendto(svr_fd, send_buf, sizeof(send_buf), 0, (struct sockaddr*)&client_addr, sizeof(client_addr));
close(); - Client端
1
2
3
4
5
6
7
8
9
10
11
12int client_fd = socket(AF_INET, SOCK_DGRAM, 0);
struct sockaddr_in svr_addr;
svr_addr.sin_family = AF_INET;
svr_addr.sin_port = htons(24);
svr_addr.sin_addr.s_addr = htonl(INADDR_ANY) // INADDR_ANY表示本机的任意一个IP
char send_buf[128];
char recv_buf[128];
sendto(client_fd, send_buf, sizeof(send_buf), 0, (struct sockaddr*)&svr_addr,&sizeof(svr_addr));
recvfrom(client_fd, recv_buf, sizeof(recv_buf), 0, (struct sockaddr*)&svr_addr, &sizeof(svr_addr));
close();
传输层
Transmission versus Propagation Delay
理解传输层的工作原理
多路复用 / 解复用
- 发送方: 从多个套接字Socket接收来自多个进程的报文,根据套接字对应的IP地址和端口号等信息对报文段用头部加以封装(该头部信息用于以后的解复用)
- 接收方: 根据报文段的头部信息中的IP地址和端口号将接收到的报文段发给正确的套接字(和对应的应用进程)
可靠数据传输(RDT)原理
- rdt 1.0
- rdt 2.0
- ACK,继续发新的
- NAK,发送旧的,直到收到ACK
- 问题:如果ACK,NAK丢失,则发送方则无法判断,不知所措
- rdt 2.1
- 解决rdt 2.0的问题:增加序号,如果ACK or NAK出错,发送方仍发送旧的,如果接收方已经存在该序号,则丢掉,同时发送ACK;如果不存在则接收发送ACK
- 一次只发一个分组,等待确认,再发送下一个,称为停止等待协议
- rdt 2.2
- 无NAK的协议,但是要对ACK编号,为流水线协议做好准备
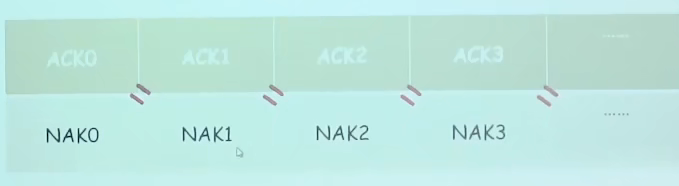 NAK1就等于前一个分组的ACK0,所以用重复的ACK0就可以替代NAK1的作用。
NAK1就等于前一个分组的ACK0,所以用重复的ACK0就可以替代NAK1的作用。 - 如果接收方发送的ACK出错,到达发送方后,发现有误,则重发上一个分组,接收方发现已经接收,丢掉,继续发ACK即可
- 无NAK的协议,但是要对ACK编号,为流水线协议做好准备
- rdt3.0
- 新的假设:具有比特差错和分组丢失的下层信道,导致丢失分组(数据
或ACK),发送P1时丢失,此时发送方等待ACK1,接收方等待P1,则形成死锁。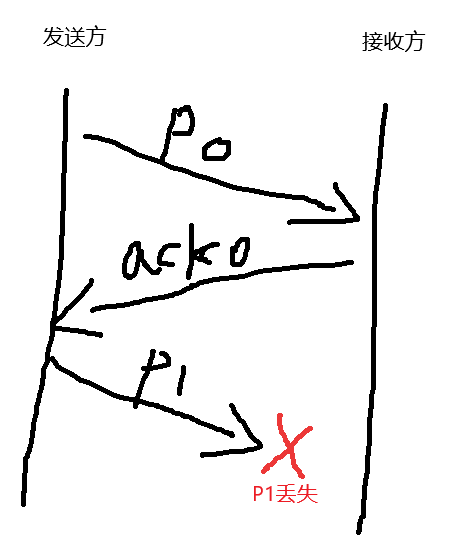
- 解决方法:增加超时定时器,一旦到时则超时重传
- 新的假设:具有比特差错和分组丢失的下层信道,导致丢失分组(数据
- 停止等待协议的问题:在信道容量比较大(以北京到深圳的高速公路为例子,中间可以容纳很多车,但两个收费站之间每次只通过一辆车,效率很低)的时候利用率太低,所以引出了流水线协议
 RTT = 30ms 分组长度1kB = 8k bits 链路带宽:1Gbps 利用率为$
RTT = 30ms 分组长度1kB = 8k bits 链路带宽:1Gbps 利用率为$Usender$,问题在于协议发送的数据太少,增大未经确认的分组个数来提高信道的利用率。
滑动窗口协议(slide window)
- 发送方窗口大小 = 1,接收方窗口 =1 的时候就是:停止等待协议
- 发送方窗口大小 > 1 的时候就是:流水线协议
- 接收方窗口 = 1 的时候就是 GBN 协议
- 接收方窗口 > 1 的时候就是 SR 协议
流水线协议(pipelined)
TCP采用的流水线协议一般是(GBN + SR)混用
- GBN协议:如果12345发送,其中2号丢失,则需要2345重新发送
- SR协议:如果12345发送,其中2号丢失,则只需重新发送2即可
TCP超时定时器RTO的合理设置:
- 比RTT要长,RTT是变化的
- 太短会导致超时太早到达,造成不必要的重传
- 太长会导致报文丢失反应太慢
- 一般选择自适应的计算获取:超时时间 = RTT + 4 * 标准差RTT
- SampleRTT:测量从报文段发出到收到确认的时间
- 采样,计算SampleRTT的平均值EstimatedRTT,α一般取值0.125。 *EstimatedRTT = (1- α)*EstimatedRTT + α*SampleRTT*
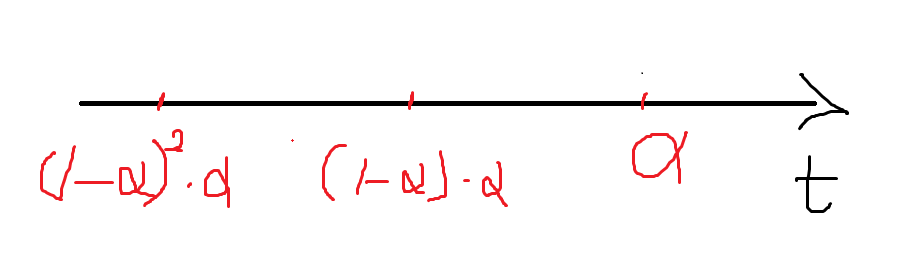
- 计算 SampleRTT 距离 EstimatedRTT 的偏差程度的值X =【x1,x2,x3,…..,xn】,再求取X的平均值,相当于标准差。 DevRTT = (1-β) * DevRTT + β * | SampleRTT-EstimatedRTT | (绝对值)
- RTO = EstimatedRTT + 4 * DevRTT
产生ACK的场景
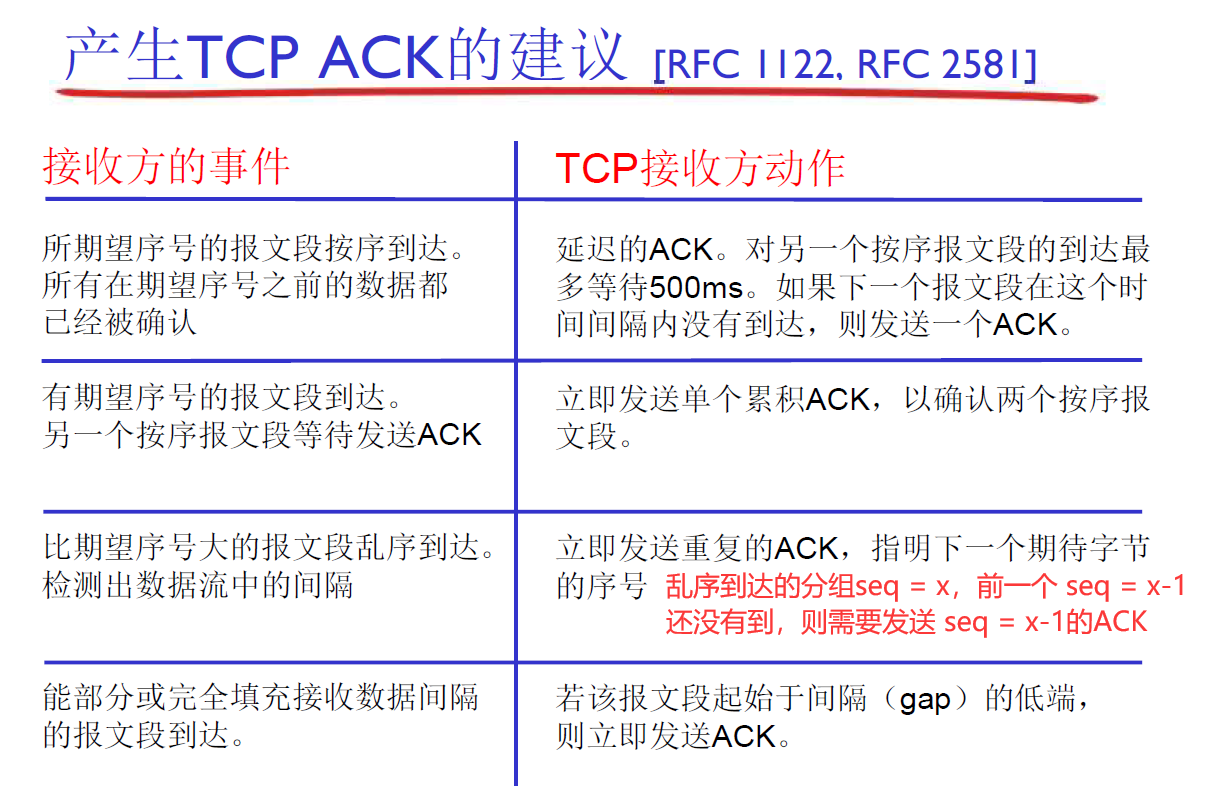
重传分组的场景:
- 发送方超时定时器到时,则开始重传,该行为称为超时重传。
- 发送方收到连续的3个冗余ACK,此时还没有到达超时定时器的时间,但仍会触法重传,该行为称为快速重传。
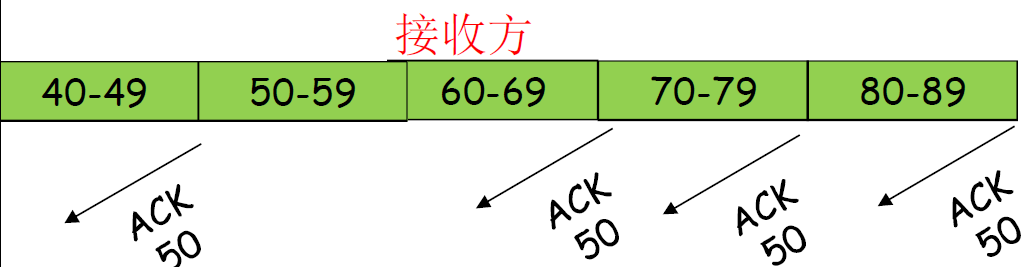
流量控制
接收方控制发送方,不让发送方发送的太多、太快以至于让接收方的缓冲区溢出。通过捎带技术将缓冲区窗口大小携带给发送方,让发送方按照这个窗口大小发送字节流。
TCP连接管理(三次握手 + 四次挥手)
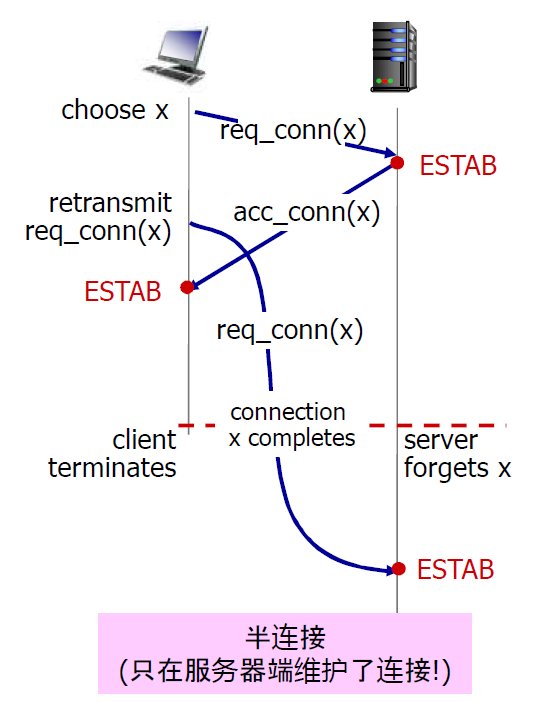
- 2次握手建立连接的问题:
- 变化的延迟,连接请求的段没有丢,但是超时,超时定时器后继续发送建立连接,会导致服务器维护很多无效的半连接,浪费服务器的资源
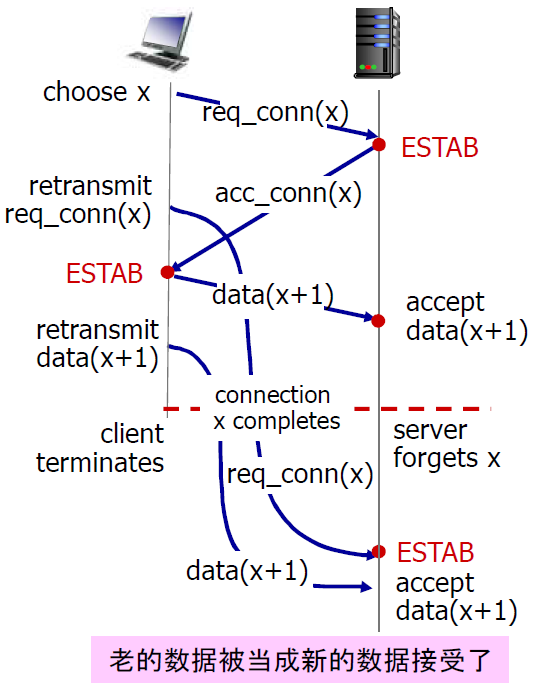
- 由于丢失造成的重传,导致数据重发给服务器
- 变化的延迟,连接请求的段没有丢,但是超时,超时定时器后继续发送建立连接,会导致服务器维护很多无效的半连接,浪费服务器的资源
- 3次握手建立连接(解决上述两个问题)
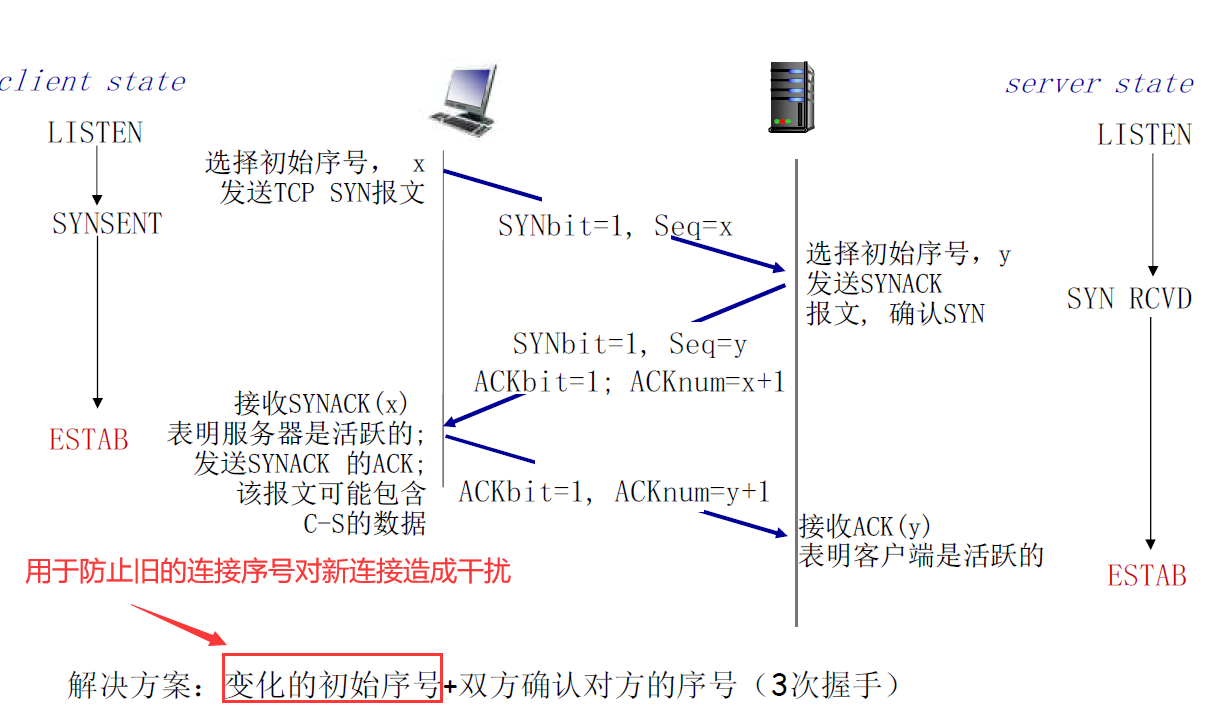
- 虚假的半连接被客户端拆除掉
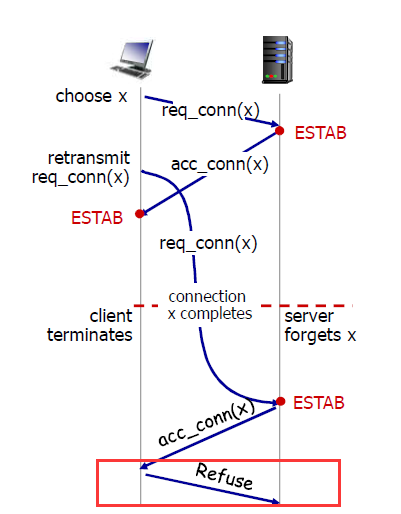
- 老的数据不会被server端接收,直接丢掉
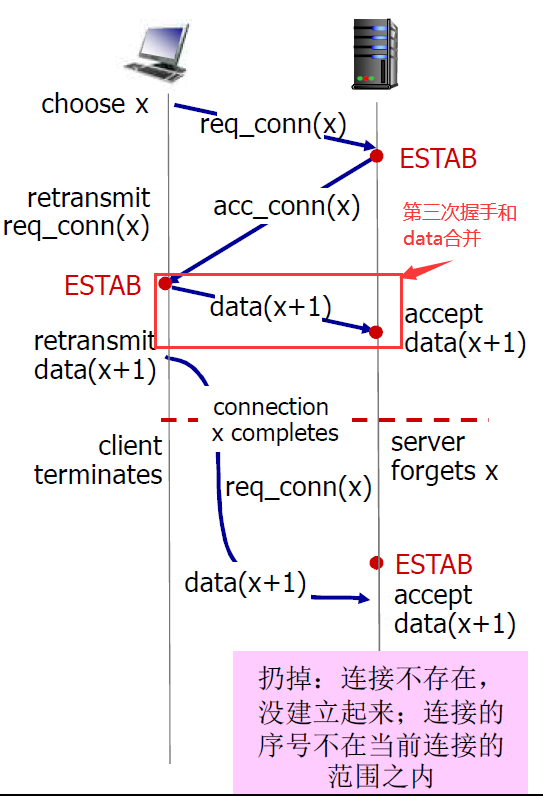
- 虚假的半连接被客户端拆除掉
- 四次挥手断开TCP连接
- 看作两个半连接的拆除
- 两军问题
- 客户端,服务器分别关闭它自己这一侧的连接,发送FIN bit = 1的TCP段,一旦接收到FIN,用ACK回应,接到FIN段,ACK可以和它自己发出的FIN段一起发送,可以处理同时的FIN交换
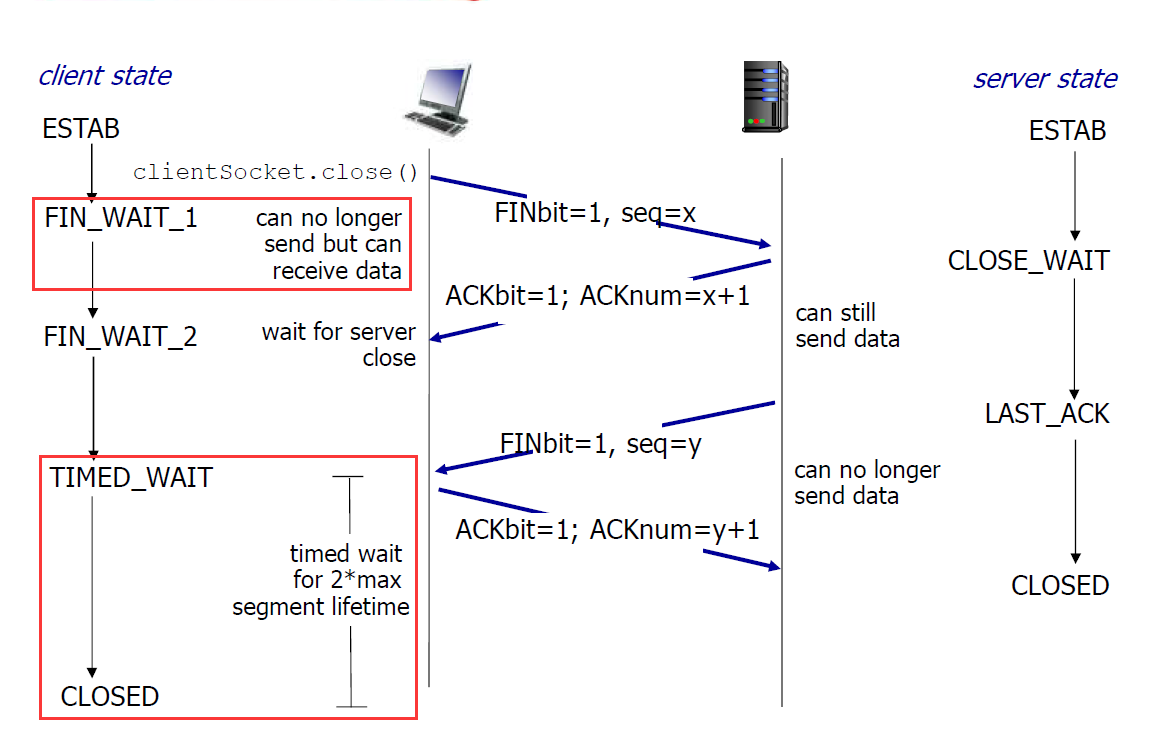
- 注意上面图中的TIMED_WAIT状态,一般是2个MSL的时间,主要原因如下:
- 原因1:要确保服务器是否已经收到了我们的 ACK 报文,如果没有收到的话,服务器会重新发 FIN 报文给客户端,客户端再次收到 ACK 报文之后,就知道之前的 ACK 报文丢失了,然后再次发送 ACK 报文。否则认为成功,可以转为closed状态
- 原因2:保证在该连接上的数据处理顺利完毕。如果一旦立刻关闭,重新以该Port再建立一个新的TCP连接,则新旧数据处理会混乱出现问题。所以留一段时间来保证网络中的遗留数据都处理完再释放资源。
拥塞控制原理
太多的数据通过网络传输,超过了网络的处理能力
- 表现:
- 分组丢失(路由器缓冲溢出)
- 分组经历比较长的延迟(在路由器中排队)
- 场景1:链路带宽R,2台主机,一个路由器具备无限大的缓冲
- 吞吐表现
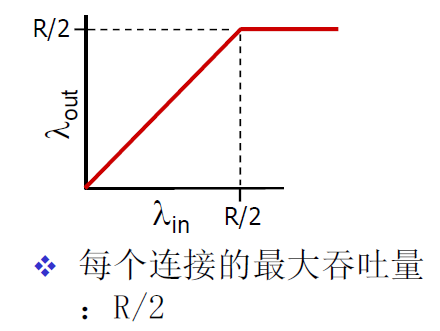
- 延迟表现
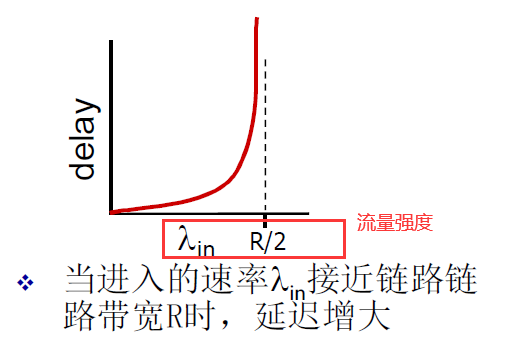
- 吞吐表现
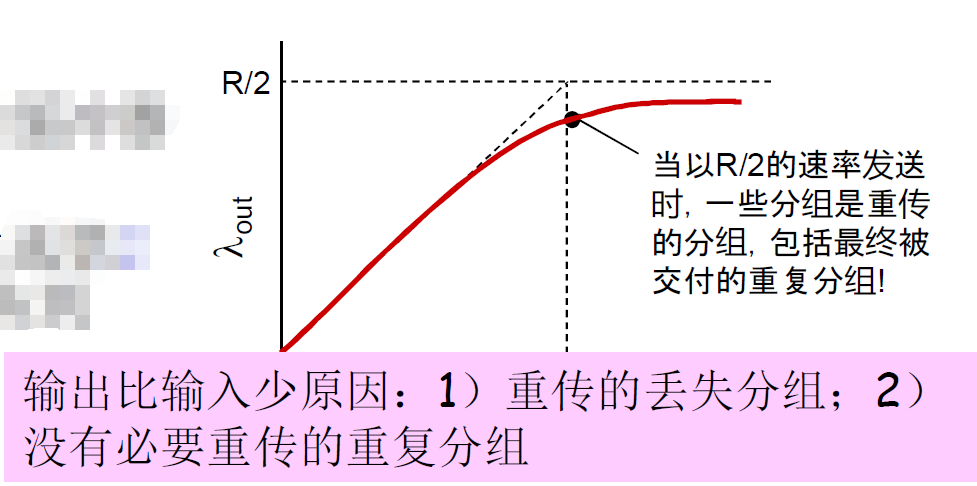
- 场景2:路由器缓冲区有限,会丢失分组,发送端重传
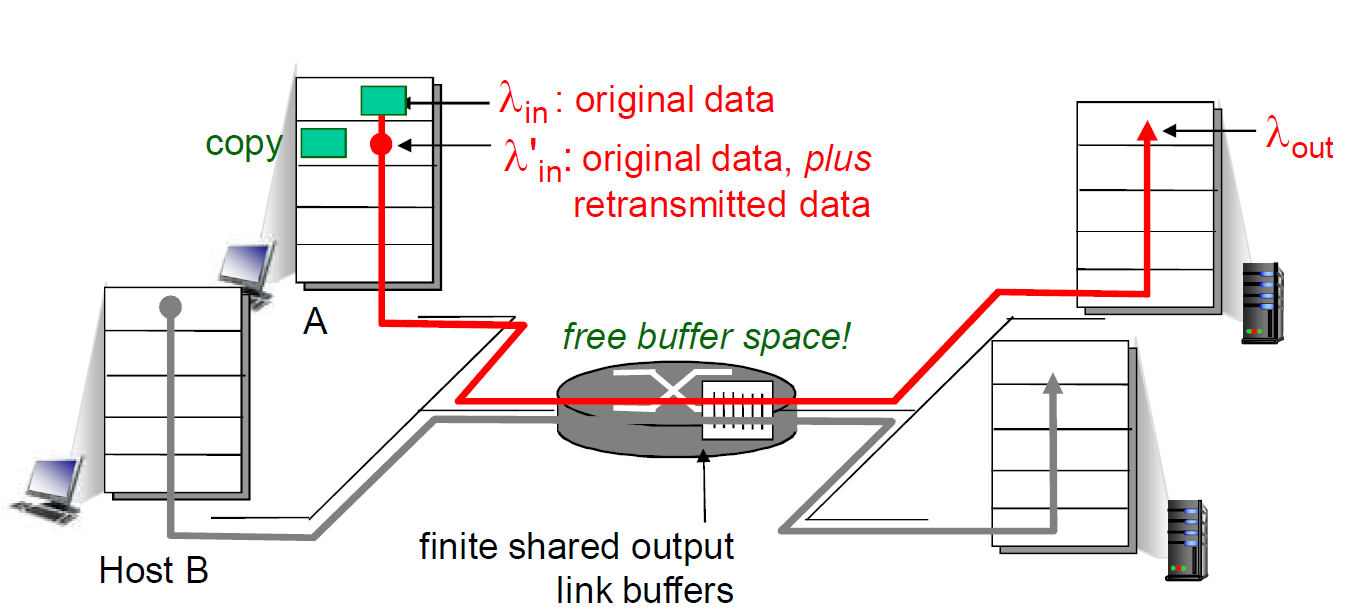
- 分组可能丢失,由于缓冲器满而被丢弃
- 发送端最终超时,发送第2个拷贝,2个分组都传到
- 为了达到一个有效输出,网络需要做更多的工作(重传)
- 没有必要的重传,链路中包括了多个分组的拷贝:
- 是那些没有丢失,经历的时间比较长(拥塞状态)但是超时的分组
- 降低了的“goodput”
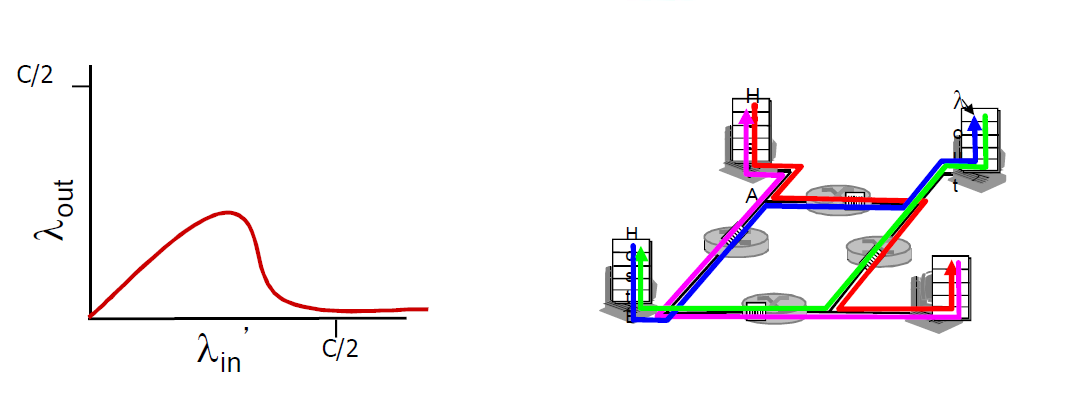
- 场景3:多台路由器,多台主机互传,会形成网络死锁
拥塞控制的方法
- 端到端的拥塞控制,TCP采用
- 没有来自网络的显示反馈
- 端系统根据延迟和丢失事件推断是否有拥塞
- 网络辅助的拥塞控制,一般用于ATM 银行网络 ABR(Available bit rate)
- 路由器提供给端系统来反馈网络的拥塞情况
- 单个bit置位,显示有拥塞
- 显示提供发送端可以采用的速率
- 路由器提供给端系统来反馈网络的拥塞情况
TCP拥塞控制
- 拥塞控制和流量控制是联合作用的,取二者的最小值来发送,使二者都满足
- $SendWin=min(CongWin, RecvWin)$
- 每收到一个确认ACK,拥塞窗口值加1个MSS的大小;和每个RTT内拥塞窗口double翻倍的概念是一致的。如何理解:
- 假设当前窗口是n,发送方一次发送n个包,每个包收到1个ACK,则这是一个RTT,收到n个ACK,则需要增加n个包,变为2*n。所以是每个RTT翻倍
- 线性增,乘性减
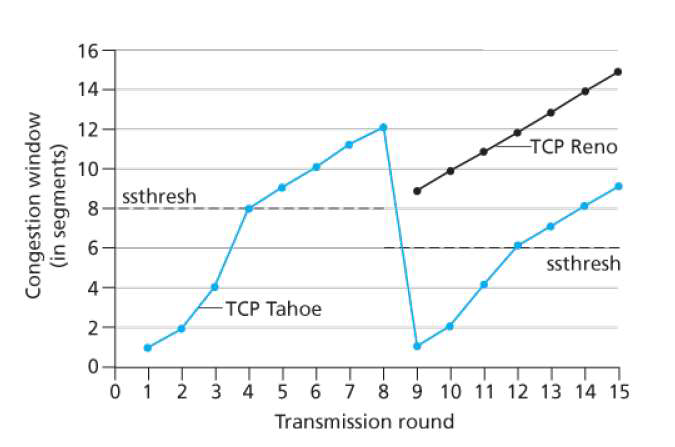

- 慢启动阶段称为SS
- 拥塞避免阶段称为CA
- 总结
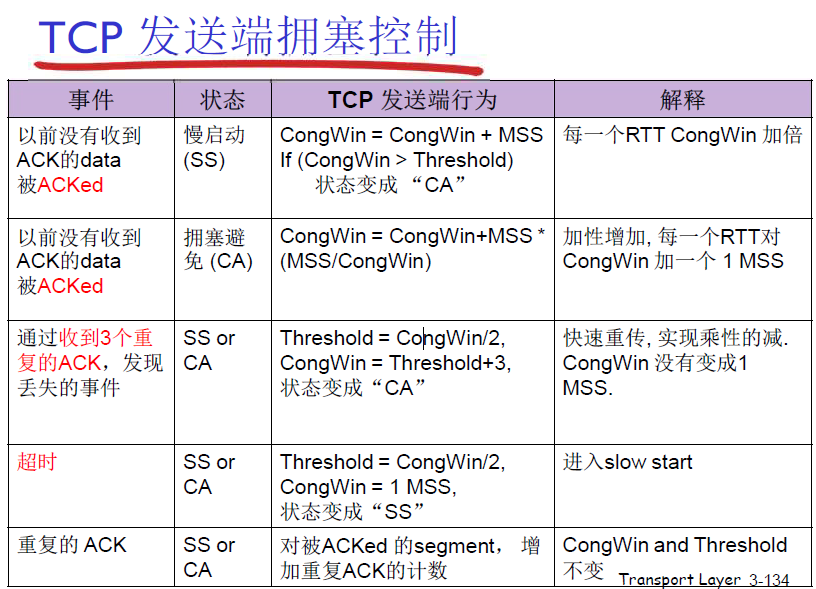

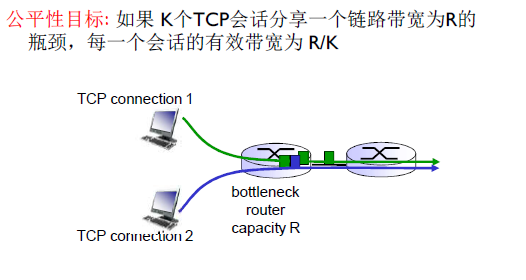
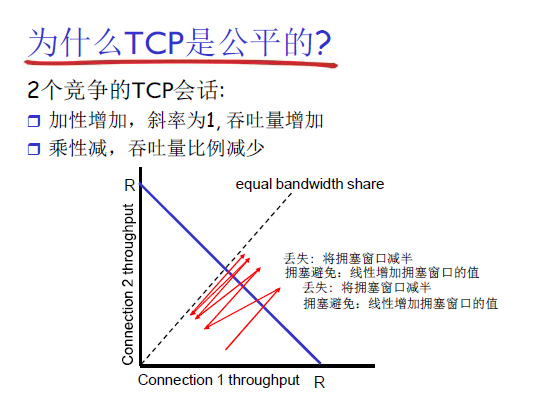
TCP的公平性
学习传输层协议
- TCP:面向连接的字节流,提供可靠数据传输(Reliable Data Transfer)的服务,20字节头部
- 序号:在MSS中的offset
- 确认号:发送方收到接收方ACK=6的话,表示接收方已经收到了5以前所有的报文,希望收到下一个字节的序号。
- 接收窗口:用于流量控制,表示能接收的字节数量
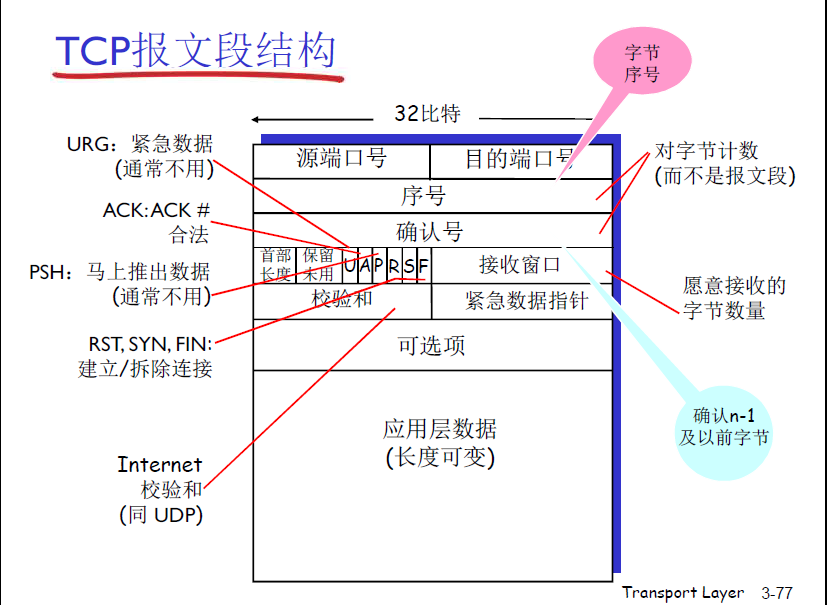
- 点对点
- 一个发送方,一个接收方
- 可靠的,按顺序的字节流
- 没有报文边界
- 管道化(流水线协议)
- TCP拥塞控制和流量控制设置窗口大小
- 发送和接收缓存
- 用于丢失重传
- 全双工数据
- 在同一连接中数据流向是双向流动
- MSS:最大报文段大小,物理网络(比如以太网最长是1500字节 = TCP头部20字节 + IP头部20字节 + 数据1460字节)
- 面向连接
- 数据交换之前通过三次握手建立连接
- 有流量控制
- 发送方不会淹没接收方
- UDP:无连接传输,数据报,8字节头部
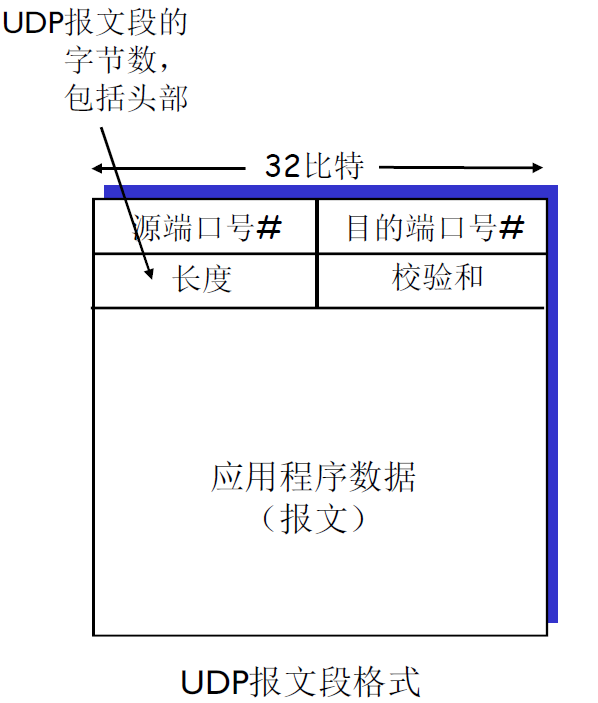

- TCP和UDP都不能提供的服务:延时保证,带宽保证
网络层(数据平面)
- 数据平面:分组转发,从路由器一个输入端口移动到一个合适的输出端口
- 控制平面:路由,确定从源点到目的点的路径
- 转发和路由有2种方式:传统方式 和 SDN(soft define network) 方式
路由器的组成
- 路由:运行路由选择算法协议(RIP,OSPF,BGP)生产路由表
- 转发:从输入到输出链路交换数据报,根据路由表进行分组的转发
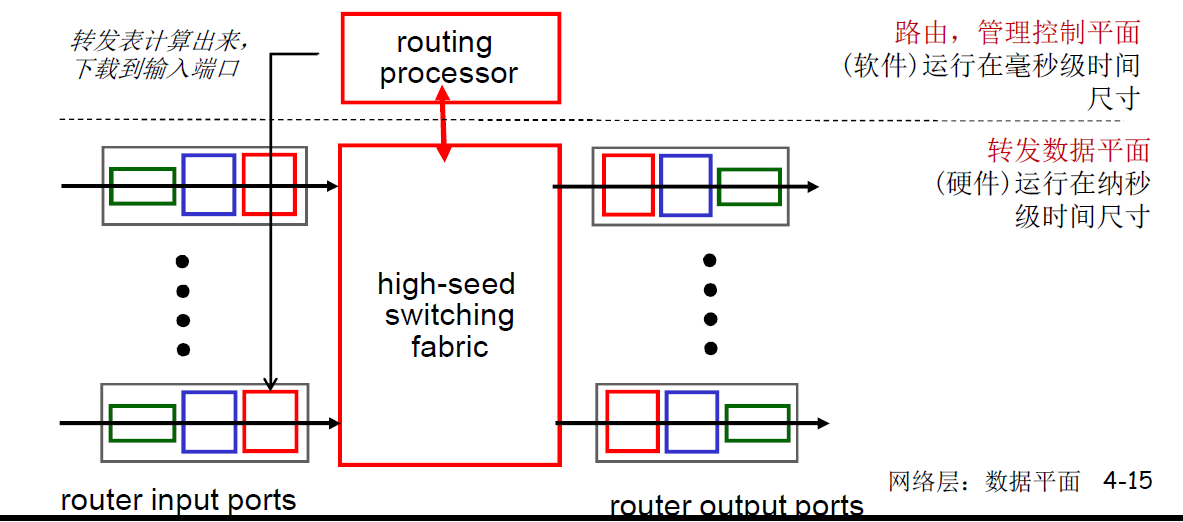
- 路由器缓冲区的分组会根据优先级来进行调度转发
- 缓冲区存在的意义是为了匹配接收和发送的速率不一致问题
IP协议
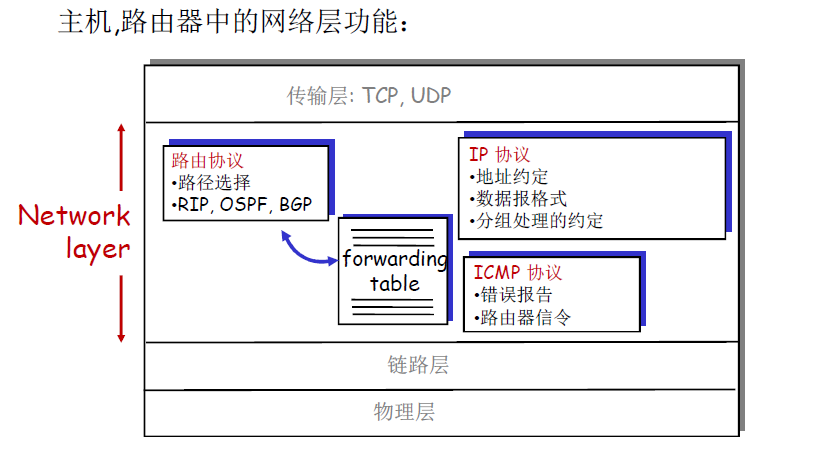
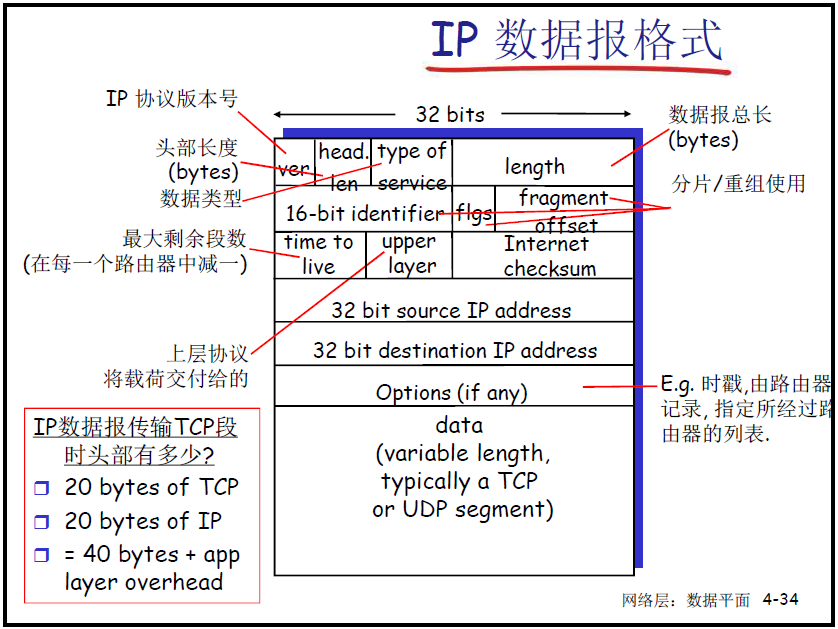
- IP 数据报格式
- 16-bit identifier,flags,fragment offset 这三个用于分片重组使用
- upper layer:表示要交付给上层哪个协议,是TCP还是UDP
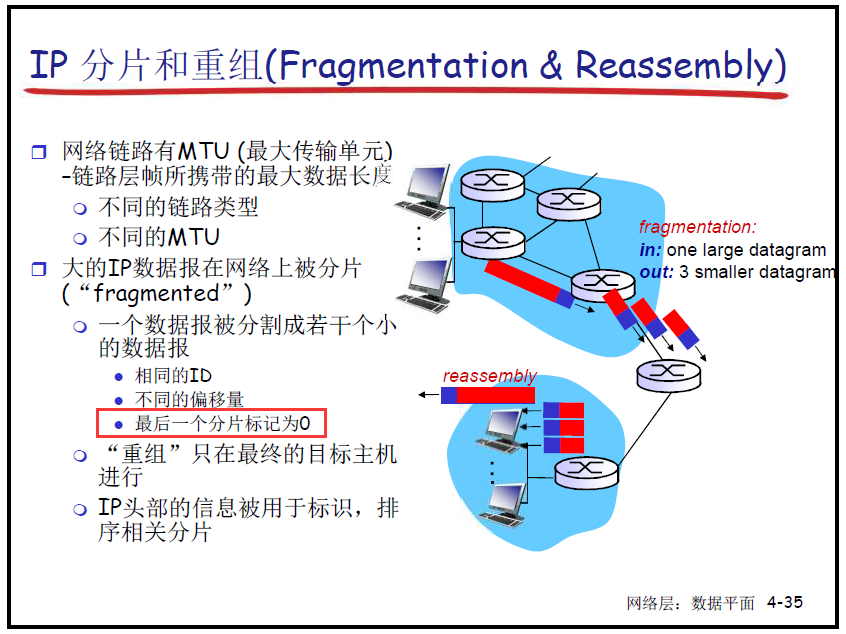
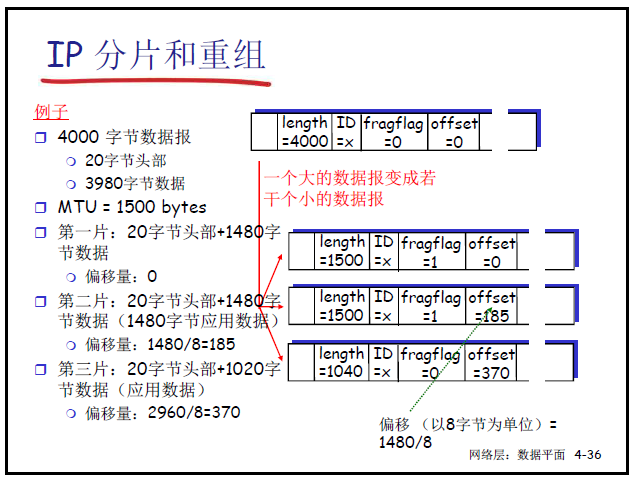
- 分片和重组
- IPv4地址:32位标示,对主机或者路由器的接口编址
- 一个IP地址和一个接口相关联
- 主机可以有多个IP地址(多张网卡就可以有多个IP),路由器至少有2个IP地址
- 子网Subnets
- 所有子网内IP的前缀是一样的
- 在子网范围内之需要一跳可达,无需借助路由器
- 如何判断两个IP处于同一子网内?
- 借助子网掩码,IP和子网掩码做&操作,如果一致则在同一子网
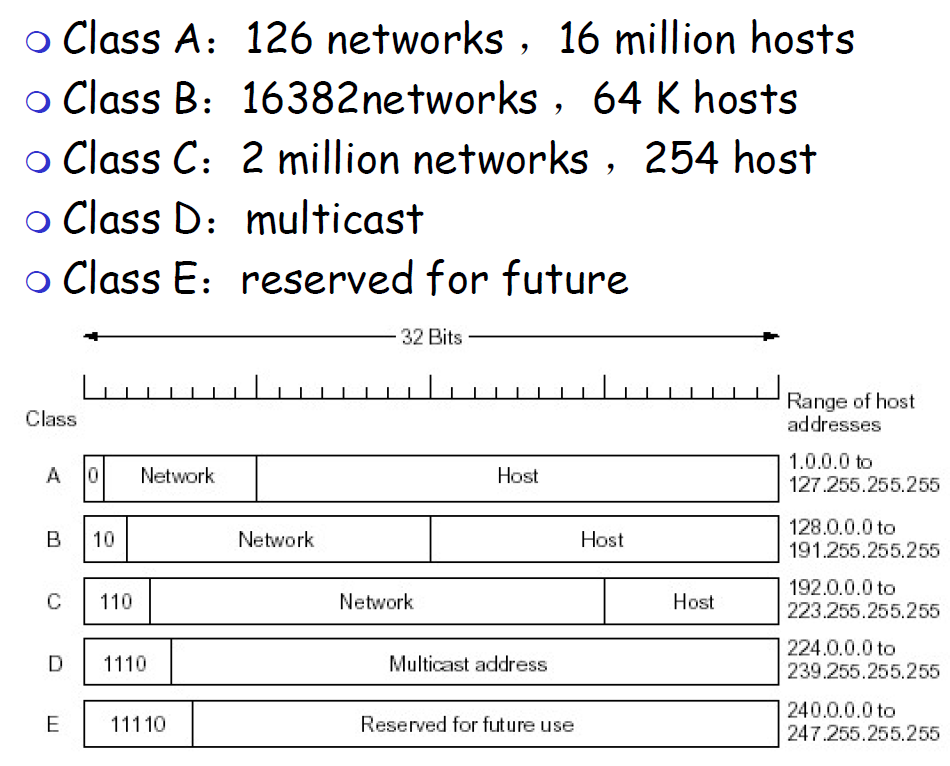
- IP地址分类
- 内网专用地址

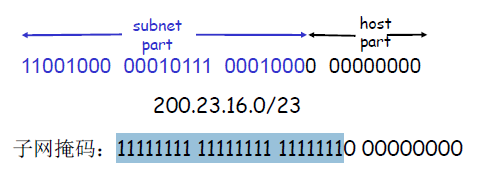
- IP编址:CIDR(Classless InterDomain Routing)无类域间路由
- 子网部分可以在任意部分
- 地址格式:a.b.c.d/x,其中x是地址中子网号的长度
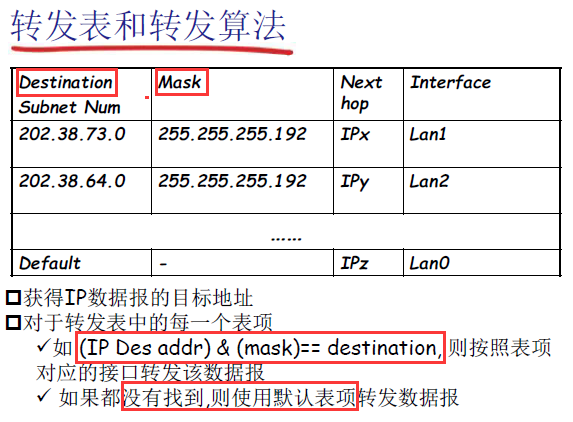
- 转发表和转发算法
- DHCP协议(实现UDP之上,涉及广播)
- 用户在上线时通过DHCP协议向DHCP Server自动获取IP地址,可以更新对主机在用IP地址的租用期-租期快到了,重新启动时,允许重新使用以前用过的IP地址,支持移动用户加入到该网络(短期在网)。
- NAT(Network Address Translation)网络地址转换,完成将内网IP转化为公网的IP,完成路由
- 不需要从ISP分配一块地址,可用一个IP地址用于所有的(局域网)设备,省钱
- 可以在局域网改变设备的地址情况下而无须通知外界
- 可以改变ISP(地址变化)而不需要改变内部的设备地址
- 局域网内部的设备没有明确的地址,对外是不可见的,安全
- IPv6地址
- 动机:
- IPv4不够用
- 头部格式改变帮助加速处理和转发
- TTL - 1
- 头部checksum
- 分片
- 头部

- 和IPv4的变化
- CheckSum被移除,加快每一段中的处理速度
- Options:允许,但是在头部之外, 被“Next Header” 字段标示
- ICMPv6:ICMP的新版本
- 附加了报文类型, e.g. “Packet Too Big”
- 多播组管理功能
- IPv4 到 IPv6 的过渡:双栈隧道技术
- 隧道技术:在IPv4路由器之间传输的IPv4数据报中携带IPv6数据报
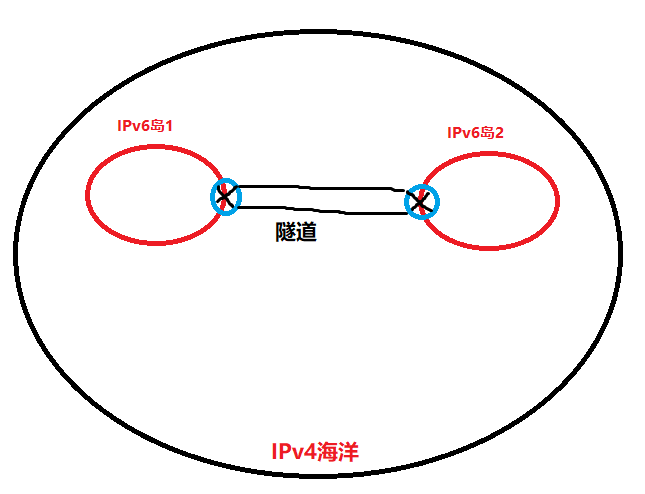
- 例子理解
- IPv4的海洋中各自IPv4通信没有问题
- IPv6的岛上各自通信也没有问题
- IPv6岛1上的主机和IPv6岛2上的主机通信需要借助隧道技术来将IPv6封装成IPv4报文通过隧道传到IPv6岛2,之后解封装,发送到目的主机
- 隧道技术:在IPv4路由器之间传输的IPv4数据报中携带IPv6数据报
- 动机:
通用转发和SDN

- 传统方式:
- 概述:

- 缺点:

- 概述:
- SDN方式:
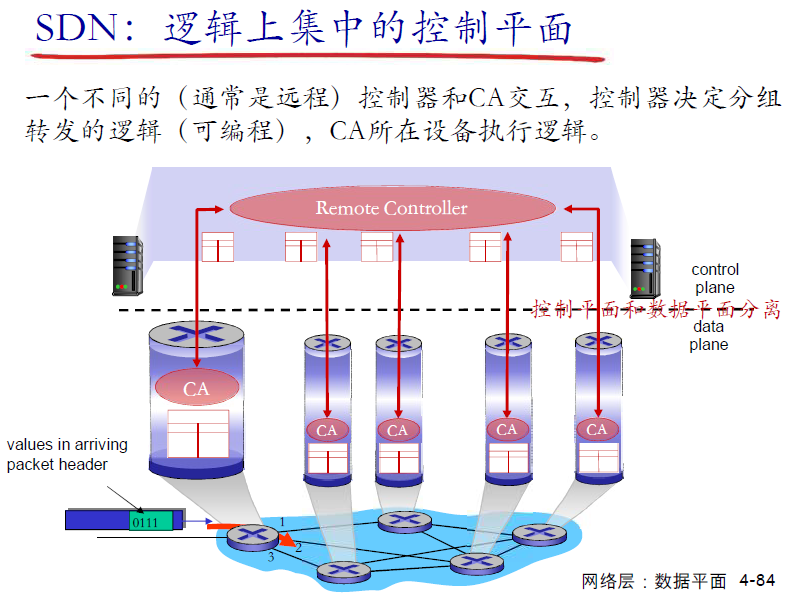
- 实现思路:

- SDN优势:

- 实现思路:
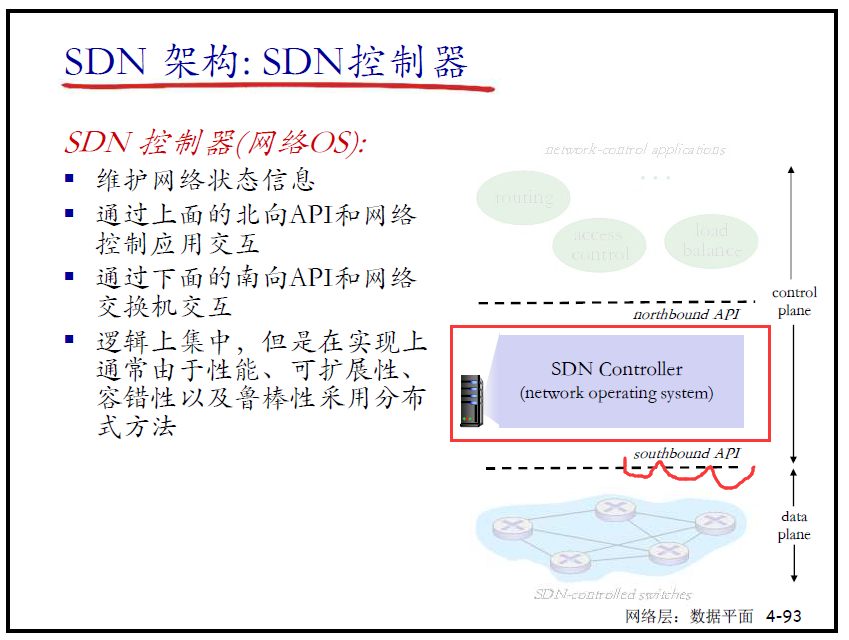
- SDN架构
- 控制器,也称为网络操作系统
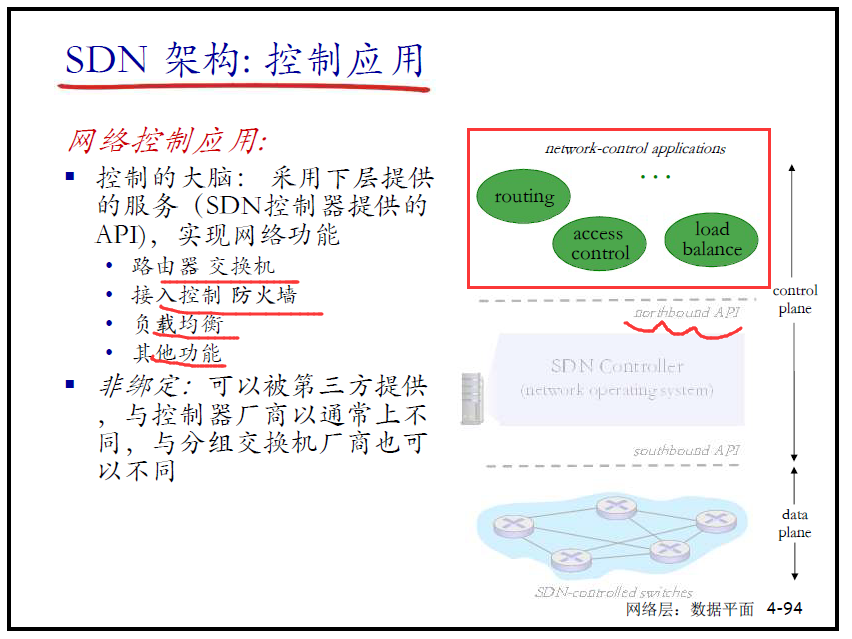
- 控制应用
- 控制器,也称为网络操作系统
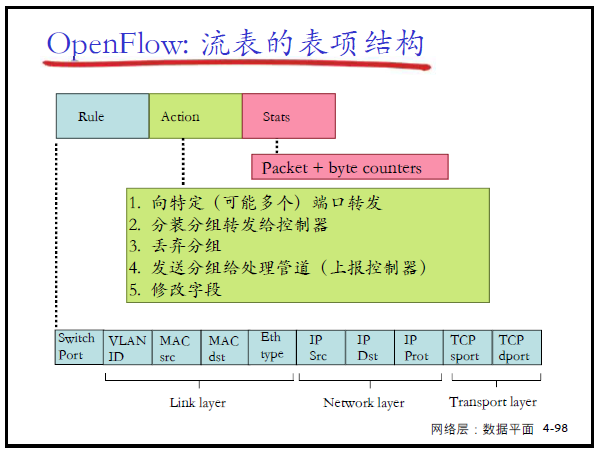
- OpenFlow 数据平面抽象
- 流:由分组(帧)头部字段所定义
- 通用转发:简单的分组处理规则
- 模式:将分组头部字段和流表进行匹配
- 行动:对于匹配上的分组,可以是丢弃、转发、修改、将匹配的分组发送给控制器
- 优先权Priority:几个模式匹配了,优先采用哪个,消除歧义
- 计数器Counters:#bytes 以及#packets
- OpenFlow 流表的表项结构
网络层(控制平面)
路由选择算法
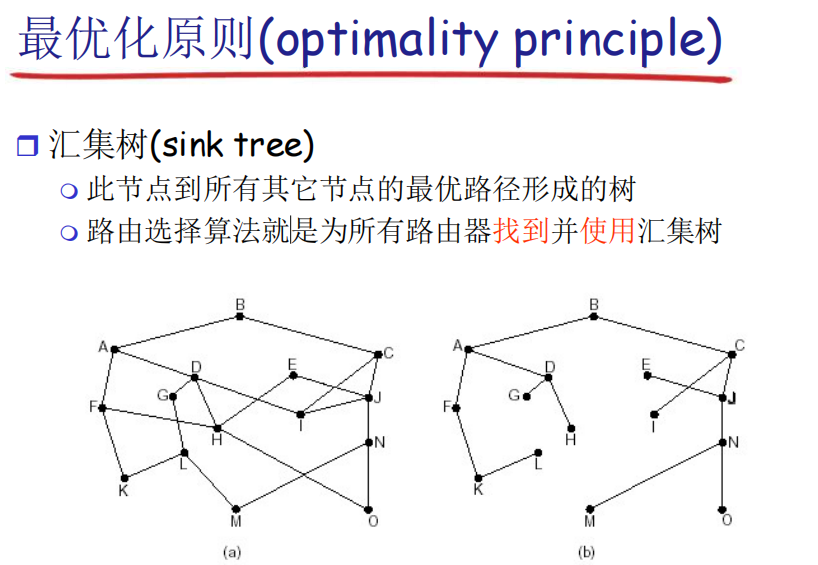
路由的概念:按照某种指标(传输延迟,所经过的站点数目等)找到一条
从源节点到目标节点的较好路径。
就是计算网络到网络是如何走的问题,也就是路由器之间是如何走的。
比如有网络拓扑如下:
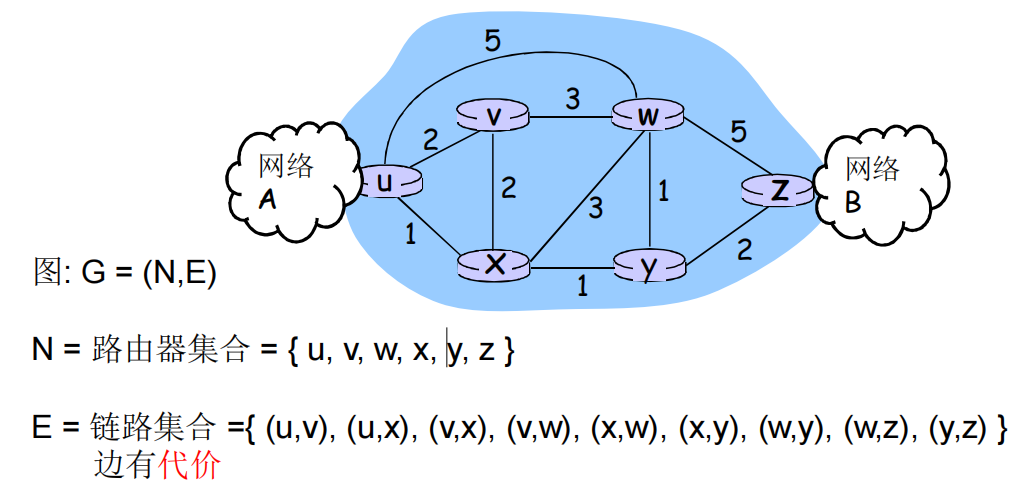
C(src,des) = 链路的代价(src,des),如C(w,z)= 5
链路状态算法 Link State
- 全局:所有的路由器拥有完整的拓扑和边的代价的信息,通过广播泛洪的方式获取所有的节点信息,然后通过Dijkstra算法计算出最短路径拓扑。
- 基本工作流程:
- 发现相邻节点,获知对方的网络地址
- 测量到相邻节点的代价(延迟,开销)
- 组装成一个LS分组,描述它到相邻节点的代价情况
- 将分组通过扩散的方式发到所有的其它路由器
- 顺序号:用于控制无穷的扩散,每个路由器都记录(源路由器,顺序号),发现重复的或老的就不扩散
- 问题1:循环使用问题
- 问题2:路由器崩溃后序号从0开始
- 问题3:序号出现错误
- 解决方法:TTL,过一个路由器,TTL-1,减为0,丢掉该分组
- 顺序号:用于控制无穷的扩散,每个路由器都记录(源路由器,顺序号),发现重复的或老的就不扩散
- 通过Dijkstra算法找出最短路径
- Dijkstra主要流程
- C(i,j) : 从 i 节点到 j 节点链路的代价
- D(v):从源节点到节点 v 的当前路径代价
- P(v):从源节点到节点 v 的路径的前序节点
- $N’$:当前已经知道最优路径的的节点集合(永久节点的集合)
- 临时节点(tentative node) :还没有找到从源节点到此节点的最优路径的节点
- 永久节点:(permanent node) N’:已经找到了从源节点到此节点的最优路径的节点

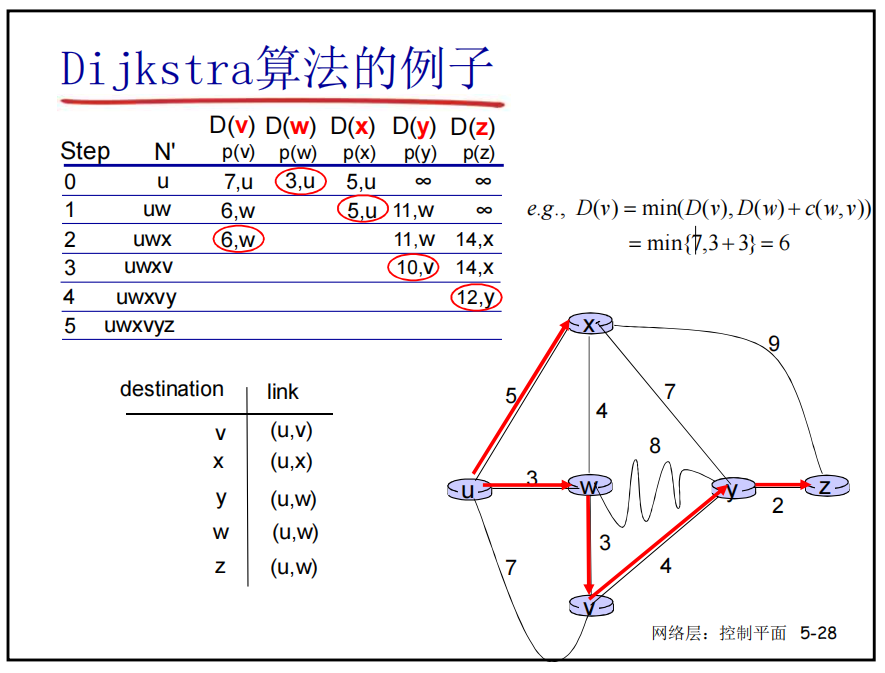 $D(v) = min(D(v),D(w) + C(w,v)) = min(7,6)=6$
$D(v) = min(D(v),D(w) + C(w,v)) = min(7,6)=6$ - 如果链路的代价是拥塞程度,Dijkstra可能会出现链路来回震荡,高负载切换到低负载链路,之后又因为低负载变为高负载,又切换,此起彼伏的出现。
- 应用:OSPF协议,IS-IS协议
距离矢量算法 Distance vector
分布式:路由器只知道与它有物理连接关系的邻居路由器,和到相应邻居路由器的代价值,需要叠代地与邻居交换路由信息、计算路由信息。
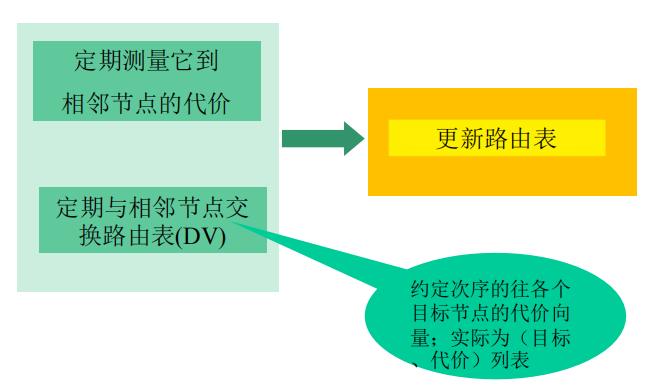
- 迭代式的算法,定时的将该节点到达其他节点的代价交换给邻居节点(路由信息通告)。
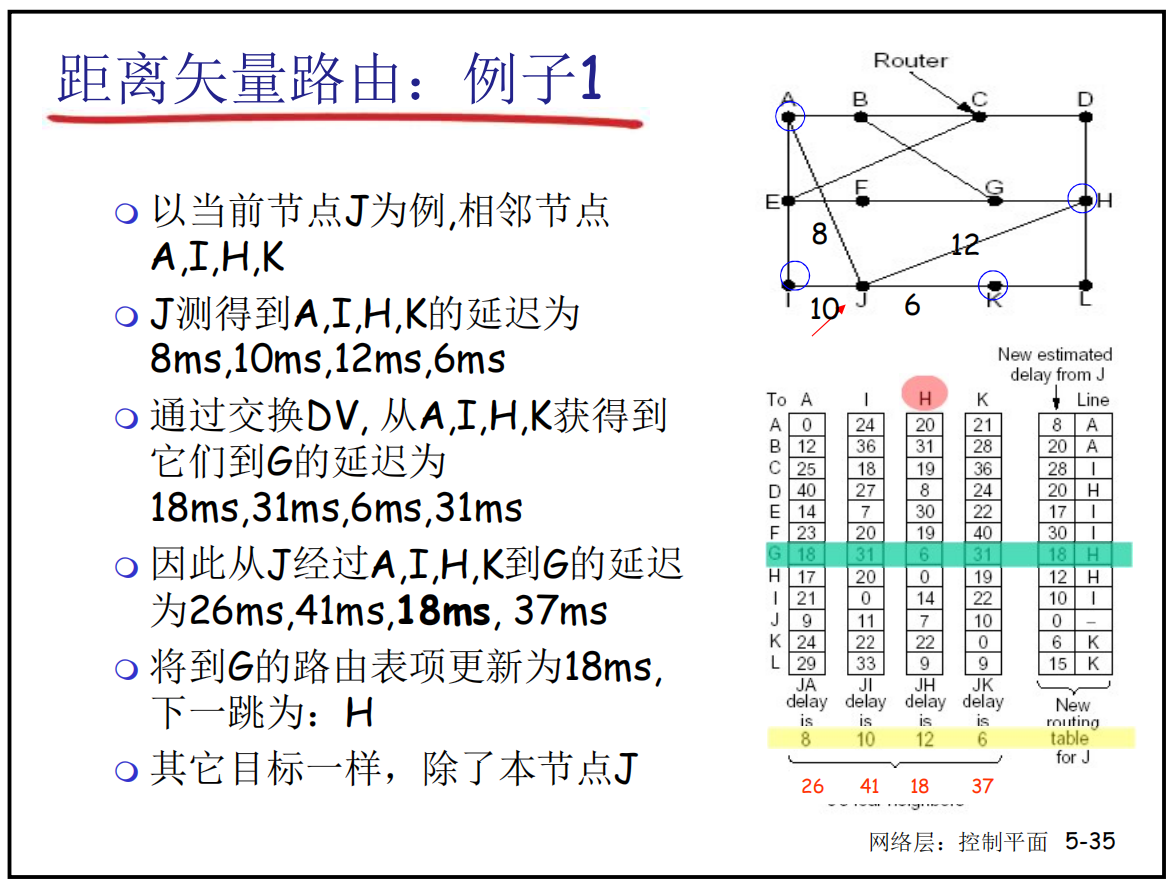
- 该例子:J→G的路由下一跳发给谁如何确定:
- J的邻居是:A,I,H,K
- 所以要根据几个邻居来获取路由信息,看右下角的图可以知道:
- A→G代价18
- I→G代价31
- H→G代价6
- K→G代价31
- J到邻居的代价分别是:8,10,12,6
- step2和step3相加后发现下一跳应该发送给H
- 该例子:J→G的路由下一跳发给谁如何确定:
- 递归方程

- DV算法的特点:
- 好消息传递的快
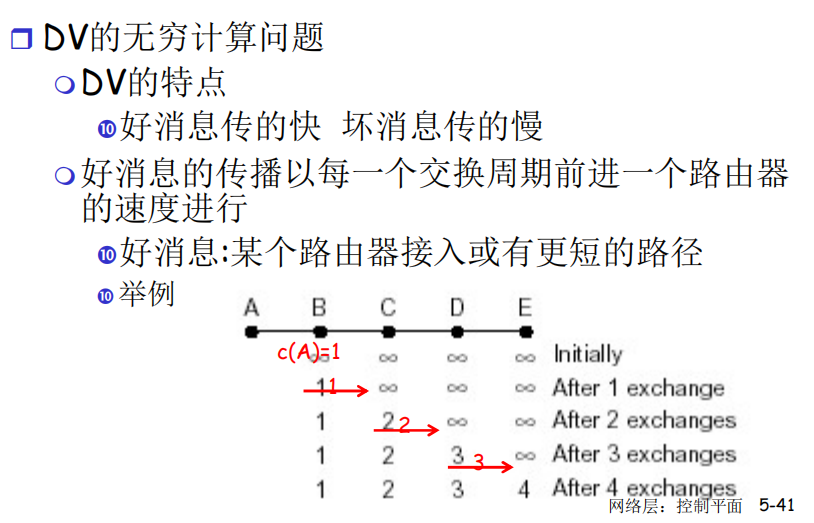
- 坏消息传递的慢:B是直连A的,B转发给A时,发现挂掉了,其实后面的CDE都是借助B来转发给A的,但是在A挂掉后这个坏消息还没有传递给CDE,CDE此时仍然认为自己有能力转发消息到A,所以坏消息传递的慢(解决方法:水平分裂,但仍不能解决环状拓扑)

- 好消息传递的快
LS和DV的比较

ISP内部自治的路由选择协议(IGP协议)
RIP:DV算法的应用
- RIP通告:
- 在邻居之间每30s交换通告报文
- 定期,而且在改变路由的时候发通告报文
- 在对方的请求下可以发送通告报文
- 每个通告:最多25个子网,路由跳数最大16(此时认为不可达)
- 在邻居之间每30s交换通告报文
- RIP: 链路失效和恢复:如果180秒没有收到通告信息,认为邻居或者链路失效
- 发现经过这个邻居的路由已失效
- 新的通告报文会传递给邻居
- 邻居因此发出新的通告 (如果路由变化的话)
- 链路失效快速地在整网中传输
- 使用毒性逆转(poison reverse)阻止ping-pong回路(不可达的距离:跳数无限 = 16 段)
- RIP进程处理
OSPF:LS算法的应用
- Open Shortest Path First:
- 使用LS算法, LS 分组在网络中(一个AS内部)分发
- 全局网络拓扑、代价在每一个节点中都保持
- 路由计算采用Dijkstra算法
- 高级特性(RIP所没有的)
- 安全: 所有的OSPF报文都是经过认证的 (防止恶意的攻击)
- 允许有多个代价相同的路径存在 (在RIP协议中只有一个)
- 对于每一个链路,对于不同的TOS有多重代价矩阵
- 例如:卫星链路代价对于尽力而为的服务代价设置比较低,对实时服务代价设置的比较高
- 支持按照不同的代价计算最优路径,如:按照时间和延迟分别计算最优路径
- 对单播和多播的集成支持:
- Multicast OSPF (MOSPF) 使用相同的拓扑数据库,就像在OSPF中一样
- 在大型网络中支持层次性OSPF
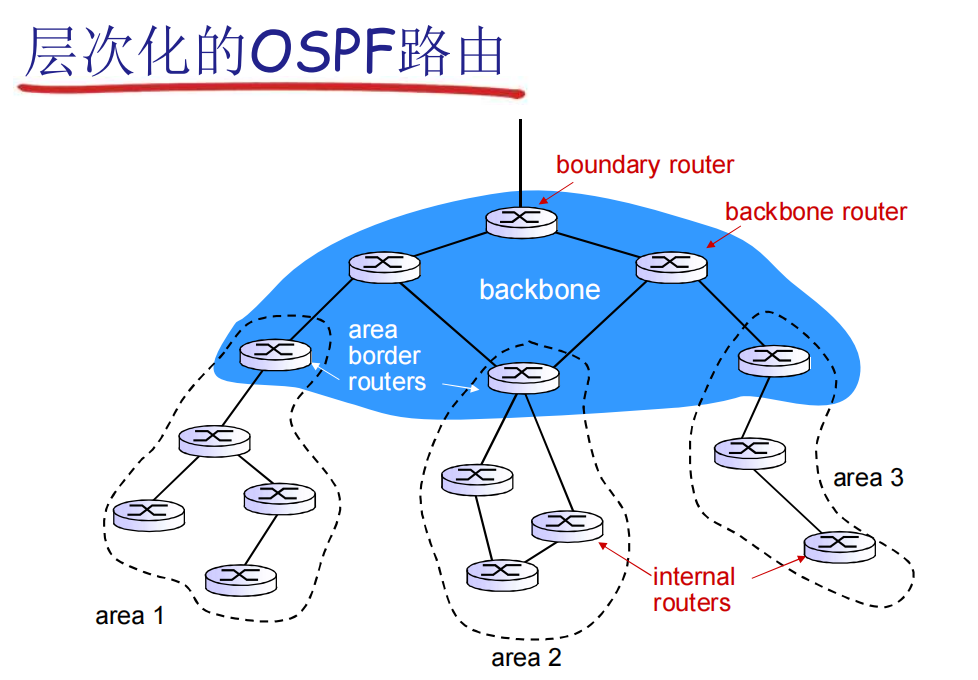
ISP之间路由协议:BGP协议
平面路由的问题
- 在规模大的网络中带来的传输,存储,计算代价很大
- DV:距离矢量很大,不能收敛
- LS:数量大的泛洪传输,存储,然后通过Dijkstra计算复杂
- 管理问题:
- 不同网络的管理方式不同
- 无法隐藏自己网络的特点
- 各个网络互联的问题
层次路由的引入
- 将互联网分成一个个的AS(autonomous systems)自治系统,用AS Number标识
- 不同的AS内部可以运行不同的 IGP(OSPF or RIP)协议,通过边界网关路由器和其他AS互联
- 优点:
- 解决了规模问题,可扩展性强
- 解决了管理问题,每个AS内部各自选择协议,无需向外透露
- BGP 提供给每个AS以以下方法:
- eBGP: 从相邻的ASes那里获得子网可达信息
- iBGP: 将获得的子网可达信息传遍到AS内部的所有路由器
- 根据子网可达信息和策略来决定到达子网的“好”路径
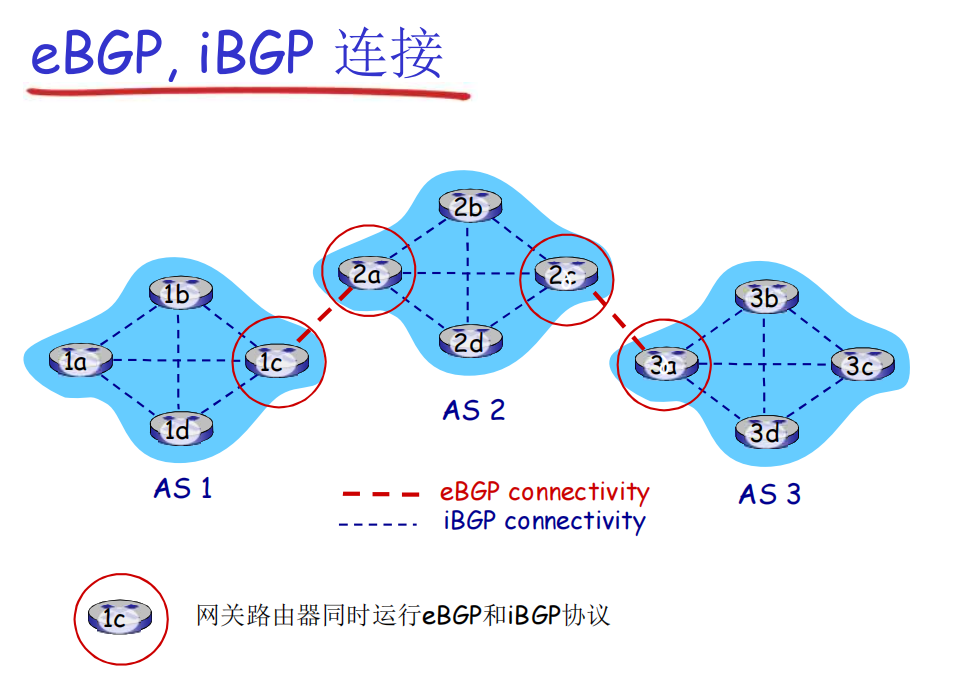
- BGP基础
- BGP 会话: 2个BGP路由器(“peers”)在一个半永久的TCP连接上交换BGP报文:
- 通告向不同目标子网前缀的“路径”(BGP是一个“路径矢量”协议),注意是会存储路径的
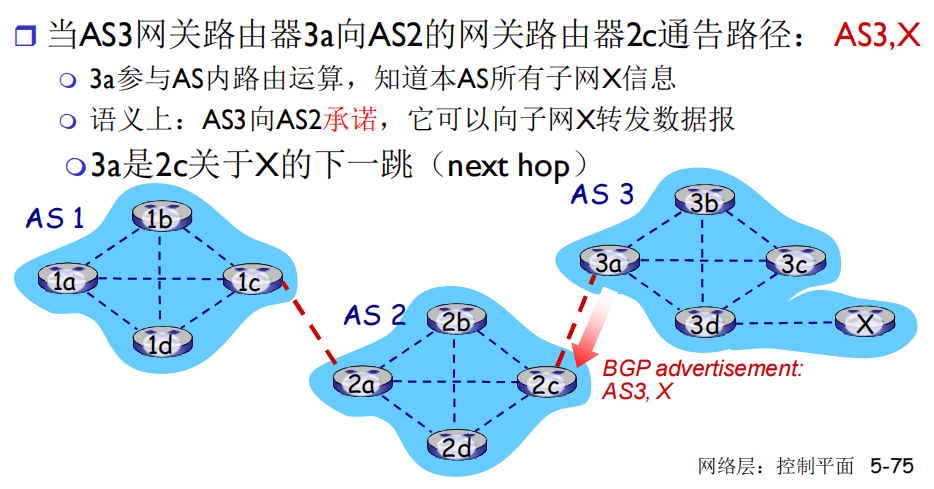
- BGP通告
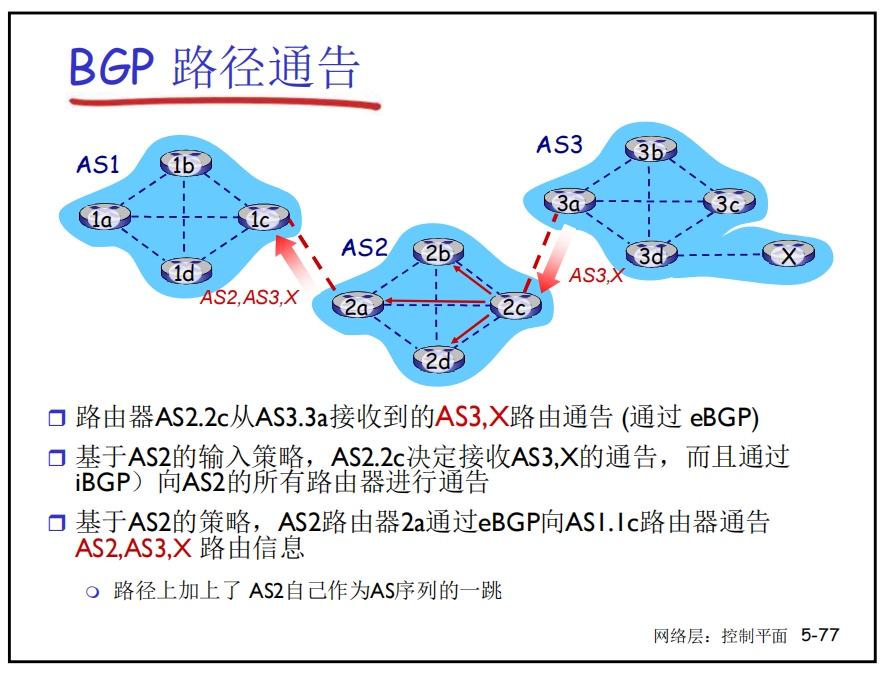
- BGP 会话: 2个BGP路由器(“peers”)在一个半永久的TCP连接上交换BGP报文:
- BGP报文:使用TCP协议交换BGP报文
- open:打开tcp连接,认证发送方
- update:通告新路径 or 撤销原路径
- keepalive:在没有更新时保持连接,也用于对open请求确认
- notification:报告以前的消息错误,也用来关闭连接
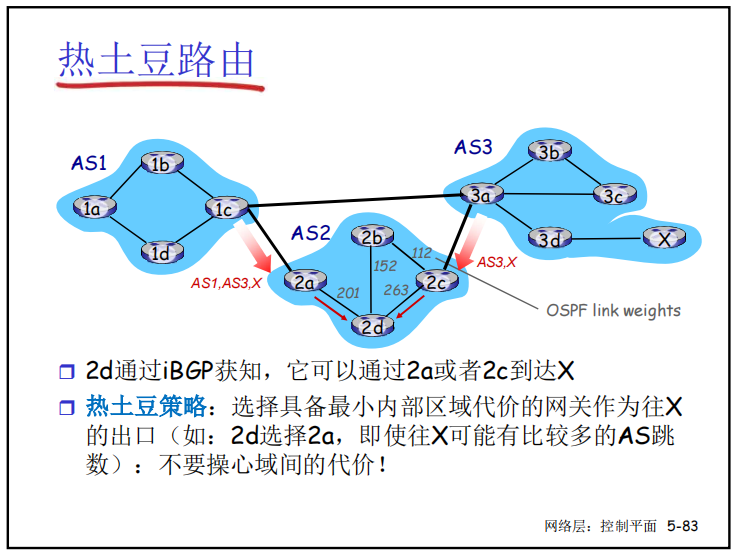
- 热土豆路由:不操心AS之间的代价,只考虑内部选择最小的路径
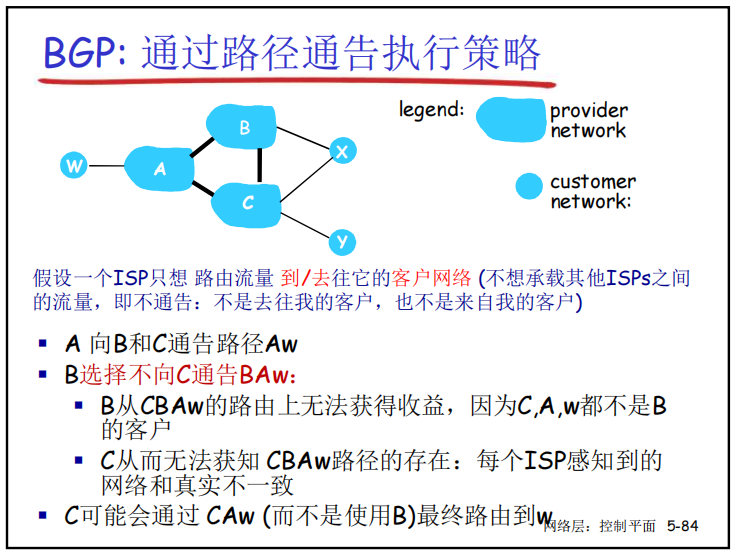
- 路径通告执行策略
数据链路层和局域网
网络层解决的是一个网络如何到达另外一个网络的问题,在一个子网内部如何从一个节点(主机or路由器)到达另外一个节点,数据链路层+物理层粉墨登场,提供”点到点“的传输功能。
网络节点互联的方式:
- 点到点的连接:一般用于WAN
- 多点连接:通过共享型介质,比如交换机等。一般用于LAN
- WAN(广域网):
- 带宽大,距离远,带宽延迟积大,如果采用多点连接出现冲突,代价大,一般都是远距离拉专线专用。
- LAN(局域网)
- 连接点方便,直接连接到共享型介质(路由器,交换机等)
- WLAN:无线局域网
- VLAN:虚拟局域网,即在物理上不聚集在一起,但仍归属同一个局域网
链路层
- 节点:主机,路由器,交换机等
- 沿着通信路径,连接各相邻节点通信信道的是链路
- 有线链路
- 无线链路
- 局域网,共享型链路
- 协议单元:帧frame
- 负责从一个节点将帧中的数据包发送到相邻节点(一般是子网内的两个节点)
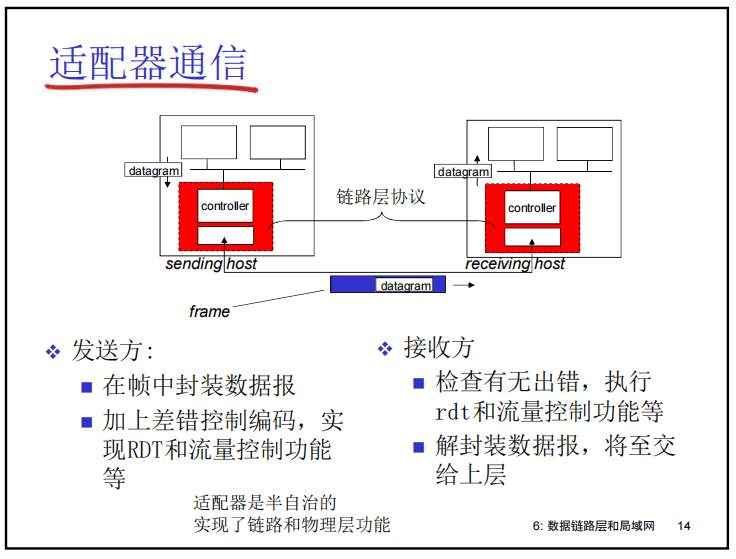
- 链路层在哪里实现?
- 在主机的适配器上实现链路层和相应物理层的功能
- 以太网卡,802.11网卡
- 在主机的适配器上实现链路层和相应物理层的功能
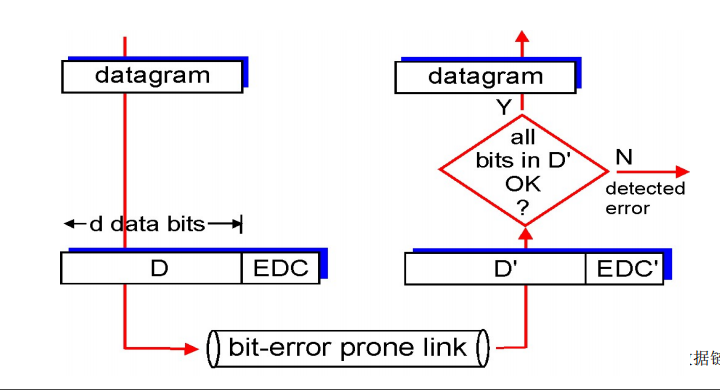
- 差错检测
- EDC = 差错检测和纠正位(冗余位),EDC越长检测纠正效果越好
- D = 数据由差错检测保护,可以包含头部字段
- 单bit奇偶校验:检测单bit错误
- 奇校验:确保传输的所有数据中的1的个为奇数,d+1位后1的个数是奇数
原信息 奇校验传输信息 11011 110111 01101 011010 - 偶校验:确保传输的所有数据中的1的个为偶数,d+1位后1的个数是偶数
原信息 偶校验传输信息 11011 110110 01101 011011
- 奇校验:确保传输的所有数据中的1的个为奇数,d+1位后1的个数是奇数
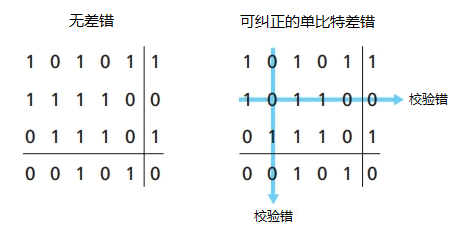
- 2维奇偶校验:检测和纠正单bit错误
- CRC循环冗余校验 选择 r 位CRC附加位R,使得<D,R>正好被G整除。接收方知道G,如果除后余数非0,则出错。可以检测出少于r+1位的错误。 广泛应用于:以太网、802.11 WiFi、ATM
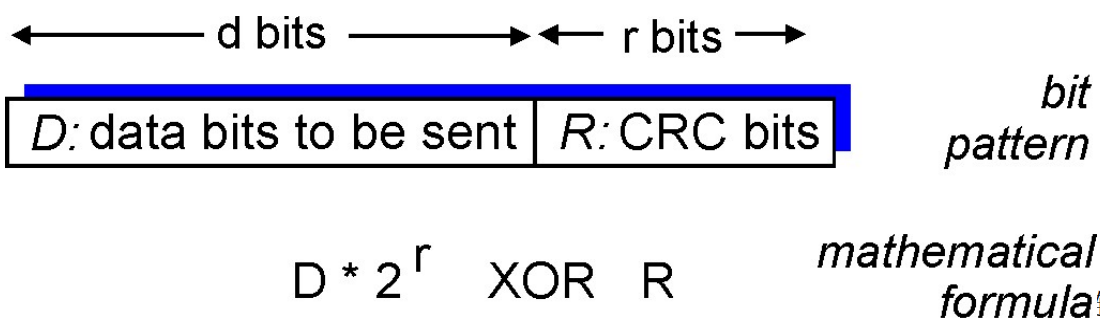
- D:数据比特
- G:双方协商的 r+1 位多项式(r次方)
- 比如1011 即:$1x^3 + 0x^2 + 1x^1 + 1x^0 = x^3 + x + 1$
- 附加位的CRC是 r 位,是需要求取的。
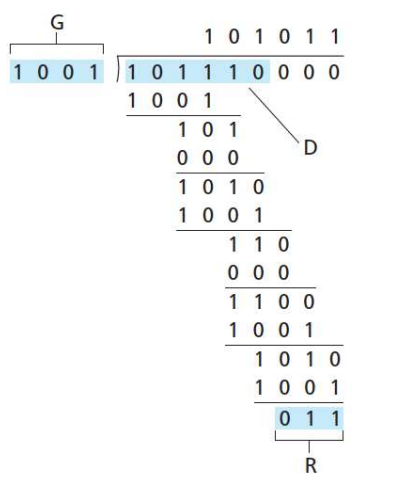
- 求取例子: D = 101110 G = 1001 由于G是4位,则R需要3位,D左移3位,补0,然后开始模2运算,将余数附在D后面传输给接收方,接收方验证有余数否,无则正确接受,否则丢弃
多路访问协议
- 两种类型的链路
- 点对点:
- 拨号访问的PPP
- 以太网交换机和主机之间的点对点链路
- 广播:
- 传统以太网
- 802.11无线局域网
- 点对点:
- 多站点同时传送会出现信道使用冲突
- MAC(媒体访问介质)协议分类
- 信道划分:时分,频分,码分,分配片给每个节点使用
- 随机访问:信道不划分,允许冲突,冲突后恢复
- 依次轮流:节点依次轮流,但是有很多数据传输的节点拥有较长时间的信道使用权
- 目前大多使用随机访问MAC,面临的问题:
- 如何检测冲突
- 如何在冲突后恢复
- 引出CSMA,CSMA/CD,CSMA/CA 协议
- CSMA 载波侦听多路访问:发送前侦听信道是否空闲,闲则发送,否则推迟发送
- 冲突发生,产生原因:局部侦听,无法判断传播延迟大的其他节点有使用信道,之后就会出现冲突,如图红黄区域则是无效传输。即传播延迟决定了冲突概率,越大则越大。
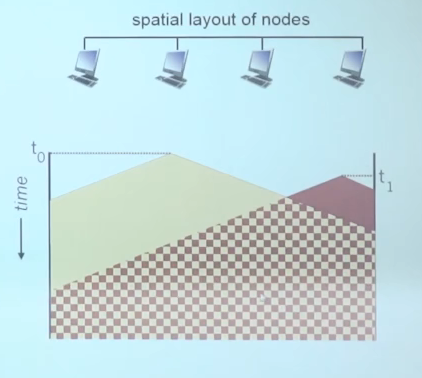
- 冲突发生,产生原因:局部侦听,无法判断传播延迟大的其他节点有使用信道,之后就会出现冲突,如图红黄区域则是无效传输。即传播延迟决定了冲突概率,越大则越大。
- CSMA/CD 载波侦听多路访问/冲突检测,传输前侦听,一边传输一遍监听,如果传输过程中发现冲突,则停止传输,减少对信道的浪费
- 一般只适用于有线局域网中容易实现
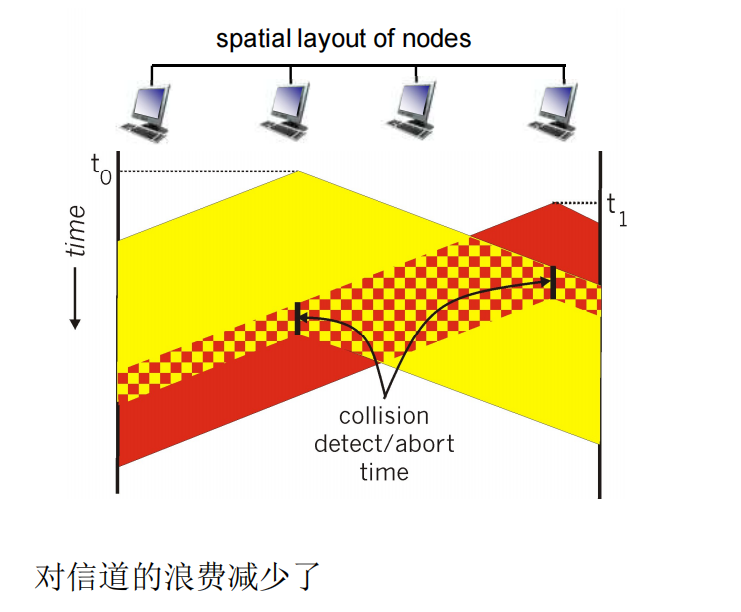
- CSMA/CD 算法过程:
- 发送前:
- 如果闲,则发送
- 如果忙,则推迟到闲再发送
- 发送中:
- 没有冲突,则成功
- 检测到冲突,则终止传输,之后尝试重发。
- 发送方适配器发现冲突后除了终止传输同时会发送一个Jam信号,强化冲突,让所有的站点都知道发生了冲突
- 放弃后进入指数退避算法状态,在第m次失败后,适配器随机选择一个{0,1,2,…… , 2^m-1} 中选择一个K,等待K*512位时转到发送状态
- 发送前:
- 指数退避的自适应算法:
- 目标:适配器试图适应当前负载,在一个变化的碰撞窗口中随机选择时间点尝试重发
- 高负载:重传窗口时间大,减少冲突,但等待时间长
- 低负载:使得各站点等待时间少,但冲突概率大
- 过程:窗口随着碰撞次数增大而增大,从而多方选择的范围变大,碰撞概率减小,增大发送成的概率。
- 首次碰撞:在{0,1}选择K;延迟K*512位时
- 第2次碰撞:在{0,1,2,3}选择K
- 第10次碰撞:在{0,1,2,3,……,1023}选择K
- 目标:适配器试图适应当前负载,在一个变化的碰撞窗口中随机选择时间点尝试重发
- CSMA/CA:载波侦听多路访问/冲突避免,一般用于WLAN无限局域网中
- 不选用CD的原因:
- 传输介质不同,无线的介质传输随着距离信号的删减非常严重,无法检测冲突
- 开放的空间冲突干扰太大,而在有线介质中不会和其他正在传输的节点发生冲突
- 发送前监听,如果忙则随机选择一个数值X,之后定时检测,每当检测到信道空闲时则减1,直到减为0时发送,同时需要ACK来避免冲突
- 隐藏终端问题,意味着不冲突不一定成功
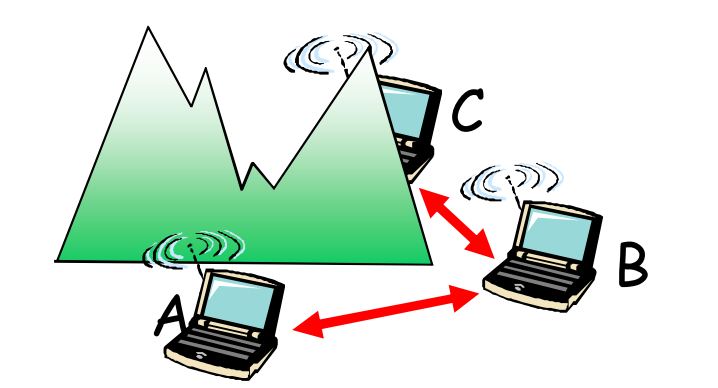 如图A和C互相无感知,当A和C都要向B发送时则会出现冲突
如图A和C互相无感知,当A和C都要向B发送时则会出现冲突 - 暴露终端问题,意味着冲突不一定不成功
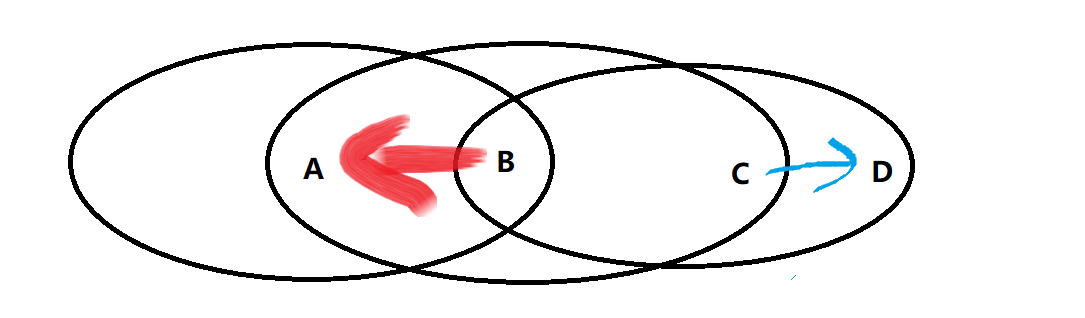 如图,B可以感知到C向D传,但是B向A传,虽然冲突,但是互不影响
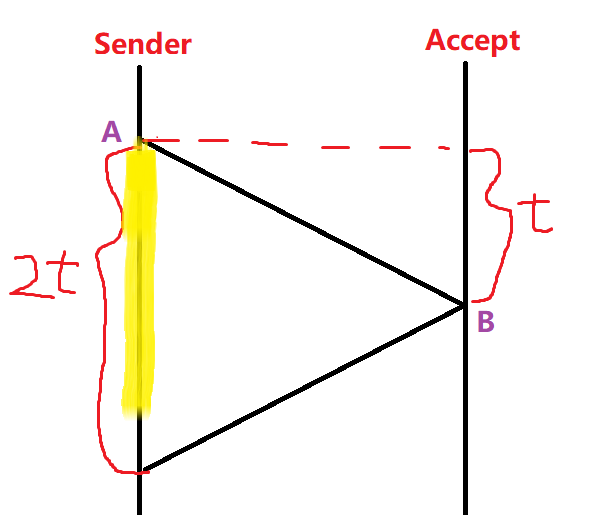
如图,B可以感知到C向D传,但是B向A传,虽然冲突,但是互不影响 - 但是在有线LAN中,基本可以认为不冲突就是成功,条件:帧的传输时间累计要≥2*t,其中 t 为最远的2个站点的传播时延,原因如图: 如果在B点之前的 t’ 时刻,此时Sender发送的数据还没有到达Accept,那Accept也要发送数据,测试侦听一下发现信道可用,但是刚发就出现了碰撞,然后这个碰撞信息又需要 t 时间才能传送给 Sender,如果Sender之前黄色区域时认定发送成功,则一定收不到该冲突信息,实质时发送失败。
- 不选用CD的原因:
- CSMA 载波侦听多路访问:发送前侦听信道是否空闲,闲则发送,否则推迟发送
LANS
- MAC 地址:用于使帧从一个网卡传递到与其物理连接的另一个网卡(在同一个物理网络中),48bit,如:1A-2F-BB-76-09-AD,每位用16进制表示。
- IP地址和MAC地址分离的原因:
- IP地址和MAC地址的作用不同
- IP地址是分层的
- 一个子网所有站点网络号一致,路由聚集,减少路由表
- 需要一个网络中的站点地址网络号一致,如果捆绑需要定制网卡非常麻烦
- 希望网络层地址是配置的;IP地址完成网络到网络的交付
- mac地址是一个平面的
- 网卡在生产时不知道被用于哪个网络,因此给网卡一个唯一的标示,用于区分一个网络内部不同的网卡即可
- 可以完成一个物理网络内部的节点到节点的数据交付
- IP地址是分层的
- 分离的好处:
- 网卡坏了,ip不变,可以捆绑到另外一个网卡的mac上
- 物理网络还可以除IP之外支持其他网络层协议,链路协议为任意上层网络协议
- 捆绑的问题:
- 如果仅仅使用IP地址,不用mac地址,那么它仅支持IP协议
- 每次上电都要重新写入网卡 IP地址;
- 另外一个选择就是不使用任何地址;不用MAC地址,则每到来一个帧都要上传到IP层次,由它判断是不是需要接受,干扰一次
- IP地址和MAC地址的作用不同
- 交换机:存储MAC地址,用于子网内转发消息。同时解决了CSMA/CD中在信道高负载时利用率低的问题,因为都是主机专用的接入交换机,没有其它主机抢用。
一个Web请求的生命流程(用于回顾整个协议栈)
- 笔记本需要一个IP地址,采用DHCP协议进行分配
- DHCP请求被封装在UDP中,封装在IP数据报,封装在802.3以太网帧
- 以太网的帧在LAN上广播(MAC地址:FF-FF-FF-FF-FF-FF)被运行中的DHCP服务器接收,之后解封装帧,解封装IP,解封装UDP获取到DHCP请求。
- DHCP服务器生成DHCP ACK,包括客户端IP地址,第一跳路由器IP地址和DNS名字服务器地址。
- DHCP服务器封装成帧转发到交换机(交换机已经自学习了请求发来时的路径,即源mac地址),交换机负责转发给client,client接收到后解封装获取IP,DNS的IP,第一跳的路由器的IP
- ARP查询广播:发生在DNS之前,HTTP之前
- 在发送HTTP请求之前,需要直到 www.google.com 的IP地址,需要DNS
- DNS查询被创建,封装在UDP段中,封装在IP数据报中,封装在以太网的帧中,将帧传递给路由器,但是需要直到路由器的接口的mac地址,则需要ARP协议通过IP获取其mac地址
- ARP查询广播,被路由器接收,路由器用ARP应答,给出其mac地址
- 现在直到第一跳路由器的mac地址,则可以发DNS查询了
- DNS请求
- DNS请求发送到DNS服务器(可能存在迭代 or 递归的获取)
- DNS服务器给出应答包:包含了www.google.com 的IP地址
- HTTP请求
- 为了发送HTTP请求,client需要创建一个到达web服务器的TCP Socket
- TCP SYN段(第1次握手)发送到web服务器
- web服务器用tcp SYN + ACK(第2次握手)发送给client
- TCP连接建立
- HTTP请求的数据 + 第3次握手 合并一起发送到web服务器
- web服务器相应HTTP请求,返回HTTP应答报文经协议栈路由回client
- client进行解析渲染完成