
BFPRT
2021-10-06 / ryanxw
BFPRT
1. 概念
用于解决TopK问题。
- TopK问题:从长度为N的无序数组中找出前K大的数
- BFPRT算法:1973年,由5位科学家 Blum 、 Floyd 、 Pratt 、 Rivest 、 Tarjan发表了一篇 “Time bounds for selection” 的论文,讲述了如何选取第K大的元素,也称为”Median of medians”,即中位数的中位数算法。该算法的时间复杂度可以严格收敛到O(n)级别。
2. 实现原理
假设现在存在一个函数 GetKthNum(arr[], k) 可以获取到第k大的数,这个函数中要做哪些事情:
- 数组的长度为n,则每5个划分为1组,不够5个元素的单独成组,一共由n/5组。时间复杂度:O(1)
- 每5个数在组内排序,组与组之间无序。时间复杂度:O(1) * n / 5 = O(n)
- 将排好序的每组中的上中位数取出来单独成组MediansArr,该组的长度为n/5。然后递归的调用GetKthNum(MediansArr, n/10) 函数,目的是为了获取到中位数数组的中位数Pivot。
- 上中位数:(1,2,3,4,5)取3,(1,2,3,4)取2
- 为什么是n/10,因为数组的长度是n/5,其中位数的一定是处于n/10的位置。
- 时间复杂度:自己调用自己,T(n/5)
- 此时用Pivot去进行快排中提到的 partition 过程,时间复杂度:O(n)
- < Pivot 的数放在左边
- = Pivot 的数放在中间
Pivot 的数放在右边
- pArr[0] == K,停止
- pArr[0] > K,左半部分进行递归
- pArr[0] < K,右半部分进行递归
- 上面的递归过程每次都可以严格的淘汰掉至少n*3/10的数据量,看图很容易明白:
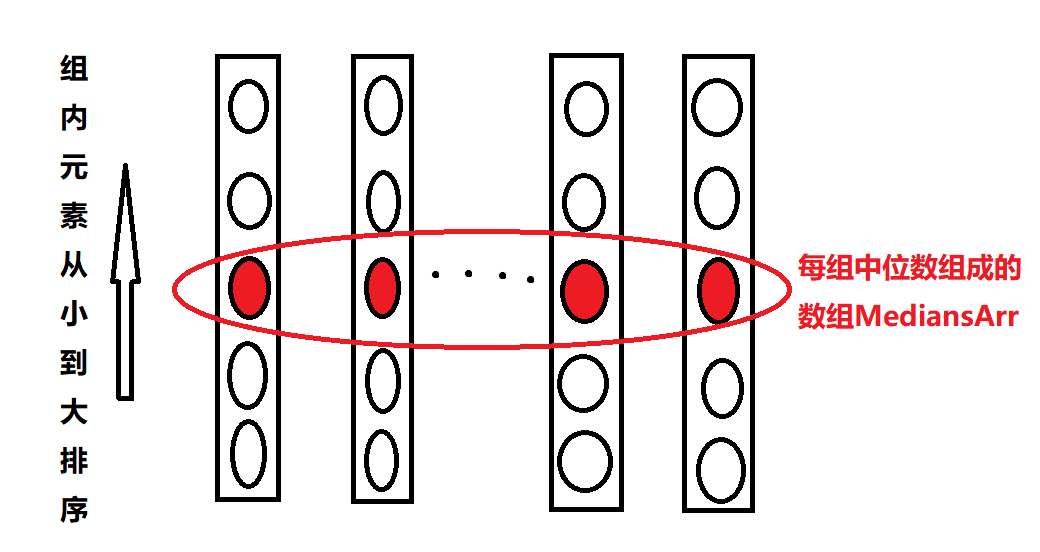 一共有n/5组,中位数数组的中位数值为Pivot,在该数组中有n/10个数的值比Pivot小,这些数字在各自的小数组中又是中位数,则表示这些组每组存在3/5个数比Pivot小,所以在原数组中就至少有n*3/10的数据量比Pivot小。也就是最多n*7/10有比Pivot大,确定了递归规模。
一共有n/5组,中位数数组的中位数值为Pivot,在该数组中有n/10个数的值比Pivot小,这些数字在各自的小数组中又是中位数,则表示这些组每组存在3/5个数比Pivot小,所以在原数组中就至少有n*3/10的数据量比Pivot小。也就是最多n*7/10有比Pivot大,确定了递归规模。 - 整体时间复杂度T(n) = T(n/5) + T(n*7/10) + O(n),可以收敛到O(n),证明(参考链接)如下:

3. 代码实现
3.1 Partition过程回顾
1 | vector partition(int arr[], int l, int r, int pivot) { |
3.2 BFPRT实现
1 | int* get_min_kth_nums_by_bfprt(int arr[], int len, int k) |